
If you need some easy, fun treats for an upcoming party, these adorable Ice Cream Cone Cupcakes are a great option! They taste like cupcakes in an ice cream cone, are easy to make, and are so cute. They are perfect for holiday or birthday parties, or just as a special treat for your kids.

As much as I love cupcakes, they aren’t always the best party treat! Crumbs easily get everywhere and little fingers have trouble with the cupcake liners. Somehow half the frosting ends up where it shouldn’t, too. I don’t know why!
That’s why this cupcake-in-a-cone hack is so ingenious, and it brings back memories of when I was a kid! It’s all the deliciousness of a cupcake but with the kid-friendly vehicle of an ice cream cone. I’m certainly not the first to share this method of baking cupcakes, but it’s so great it deserves another post!


Equipment Needed for Cupcakes in Ice Cream Cones
Luckily, you only need the same equipment to make these cupcake cones as you do to make regular cupcakes!
- Measuring cups and spoons
- Mixing bowl and spoon (or electric/stand mixer)
- Cupcake pan- for baking
- Piping bag and tip (optional for frosting)

What Ingredients Do I Need for Homemade Ice Cream Cone Cupcakes?
You can use any cake mix recipe for cupcakes, but for ease, I’m using a cake mix in this recipe. So, gather together these ingredients:
- Ice Cream Cones
- White Cake Mix
- Whole Milk
- Vegetable Oil
- Large Eggs (you only need the whites)
- Vanilla Buttercream Frosting (homemade or store-bought)
- Chocolate Frosting (homemade or store-bought)
- Toppings (Rainbow sprinkles and Maraschino Cherries)

How to Make Cupcake Ice Cream Cones
These cupcakes are fun to make and so easy, too!
- Preheat your oven to 350℉ and place an ice cream cone in each slot of your cupcake/muffin tin.
- Make the cupcake batter as directed on the box by stirring together the box cake mix, milk (instead of water), vegetable oil, and egg whites in a large bowl.
- Fill the ice cream cones with the batter about ¾ of way up, or with about ¼ cup of batter in the bottom of the cone.
- Bake for 25-30 minutes, or until a toothpick comes out clean. The tops of the cupcakes will be golden to dark golden when done.
- Allow the cupcakes to cool completely before frosting.
- Frost 6 of the cupcakes with vanilla white frosting and the other 6 with chocolate frosting, use your desired piping tip and piping bag to frost. Or you can just frost them with a knife or offset spatula.
- Add candy sprinkles and a maraschino cherry to the top of each cupcake cone and enjoy!


FAQs
What kind of ice cream cones should I use?
In this recipe, I used cake cones, also called ice cream cups or flat-bottomed ice cream cones. You need cones that will stand upright on their own while baking.
Don’t the cones get soggy while baking?
Actually, no, the cones don’t get soggy. They do get slightly softer once baked and cooled.
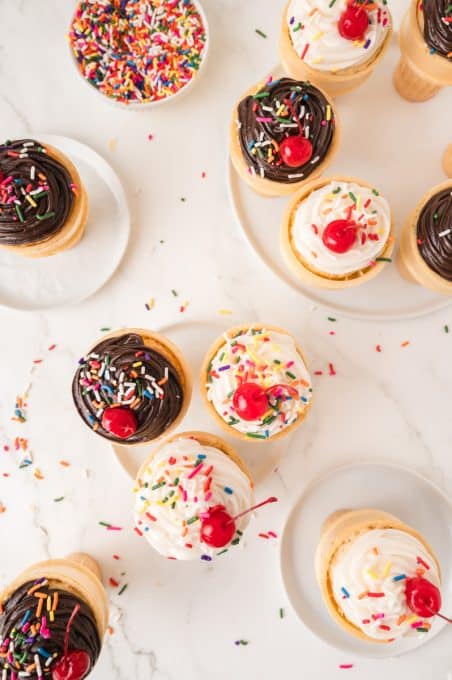
Can I make these with homemade cake batter?
Yes, you can use any kind of cake batter you want! Have fun making different flavors and decorations based on the occasion! You can also mix up the frosting as desired. I love these with cream cheese frosting too!
How do I store Ice Cream Cone Cupcakes?
Store in the fridge in an airtight container for 2-3 days. It’s easiest to store them unfrosted, and then frost right before serving. But you can store them in the fridge once frosted, too.

Can I freeze these cupcakes?
Yes! Freeze the ice cream cone cakes uncovered first, then wrap them individually in plastic wrap, and then place in a freezer safe bag. When ready to thaw, simply unwrap them and place them at room temperature for 10-15 minutes, or until soft enough to eat.

Love Cupcakes? Try one of these recipes next time:
These Chocolate Oreo Cupcakes are delicious and easy to make, and as a bonus, they include America’s favorite cookie!
Double Chocolate Peanut Butter Filled Cupcakes – moist chocolate cupcakes with milk chocolate chips, filled with a peanut butter cream and topped with chocolate buttercream.
Cupcakes and kids are a match made in heaven, and with these Butterbeer Cupcakes, you’ll imagine yourself in the wizarding world of Harry Potter!
Birthday Funfetti Cupcakes loaded with sprinkles are the perfect festive dessert! You’ll love these delicious homemade sprinkles cupcakes for all kinds of occasions.

What Else Can You Make With a Cake Mix?
Cake Mix is a great base for all sorts of desserts. If you’ve got an extra box stashed away, you can use it to make one of these easy dessert recipes:
- Cake Mix Cookies: Try Lemon, Carrot Cake, or Chocolate Mint Cookies, all made with a cake mix!
- Cake Batter Ice Cream: A scoop or two of this delicious ice cream with a creamy vanilla base, real cake mix, and sprinkles, is the perfect refresher any time of year, but especially for summer parties!
- Cake Mix Krispie Treats: Put a fun twist on the classic Rice Krispie® Treat recipe by adding a funfetti cake mix, and you’ll get these scrumptious Funfetti Rice Krispie Bars!
- Ooey Gooey Bars: Start with a white cake mix and include add-ins to make different flavors of these sweet, soft-baked dessert bars. Try Funfetti or Peppermint Ooey Gooey Bars to start!
Which one sounds good to you? Let us know in the comments!

FOLLOW ME
FACEBOOK ~ PINTEREST
INSTAGRAM ~ TWITTER
YOUTUBE
Keep an eye out for more of my easy recipes each week!
Want to Save This Recipe?
Enter your email & I’ll send it to your inbox. Plus, get great new recipes from me every week!
By submitting this form, you consent to receive emails from 365 Days of Baking and More.

Ice Cream Cone Cupcakes
Ice Cream Cone Cupcakes are fun treats for any party! These cupcakes in an ice cream cone are easy to make and are so cute, making them perfect for holidays, birthday parties, or just for surprising the kids.
Prevent your screen from going dark
Instructions
-
Preheat your oven to 350℉ and place each ice cream cone in each slot of your cupcake tin.
-
Make cupcake batter by stirring together the cake mix, milk, vegetable oil, and egg whites.
-
Fill the ice cream cones with the batter about ¾ of way up, or with about ¼ cup of the batter in each cone.
-
Bake for 25-30 minutes, or until a toothpick comes out clean. The tops of the cupcakes will be golden to dark golden when done.
-
Allow the cupcakes to cool completely before frosting.
-
Frost 6 of the cupcakes with vanilla frosting and the other 6 with chocolate frosting, use your desired piping tip and piping bag to frost.
-
Add sprinkles and a maraschino cherry to the top of each cupcake and enjoy!
Notes
Store in an airtight container in the fridge for up to 2-3 days.
Nutrition
Serving: 1serving | Calories: 506kcal | Carbohydrates: 91g | Protein: 4g | Fat: 15g | Saturated Fat: 4g | Polyunsaturated Fat: 4g | Monounsaturated Fat: 6g | Trans Fat: 0.2g | Cholesterol: 2mg | Sodium: 466mg | Potassium: 154mg | Fiber: 1g | Sugar: 67g | Vitamin A: 27IU | Calcium: 121mg | Iron: 2mg
Reader Interactions






