

Today’s AI industry is getting shaped by three underlying scaling paradigms.
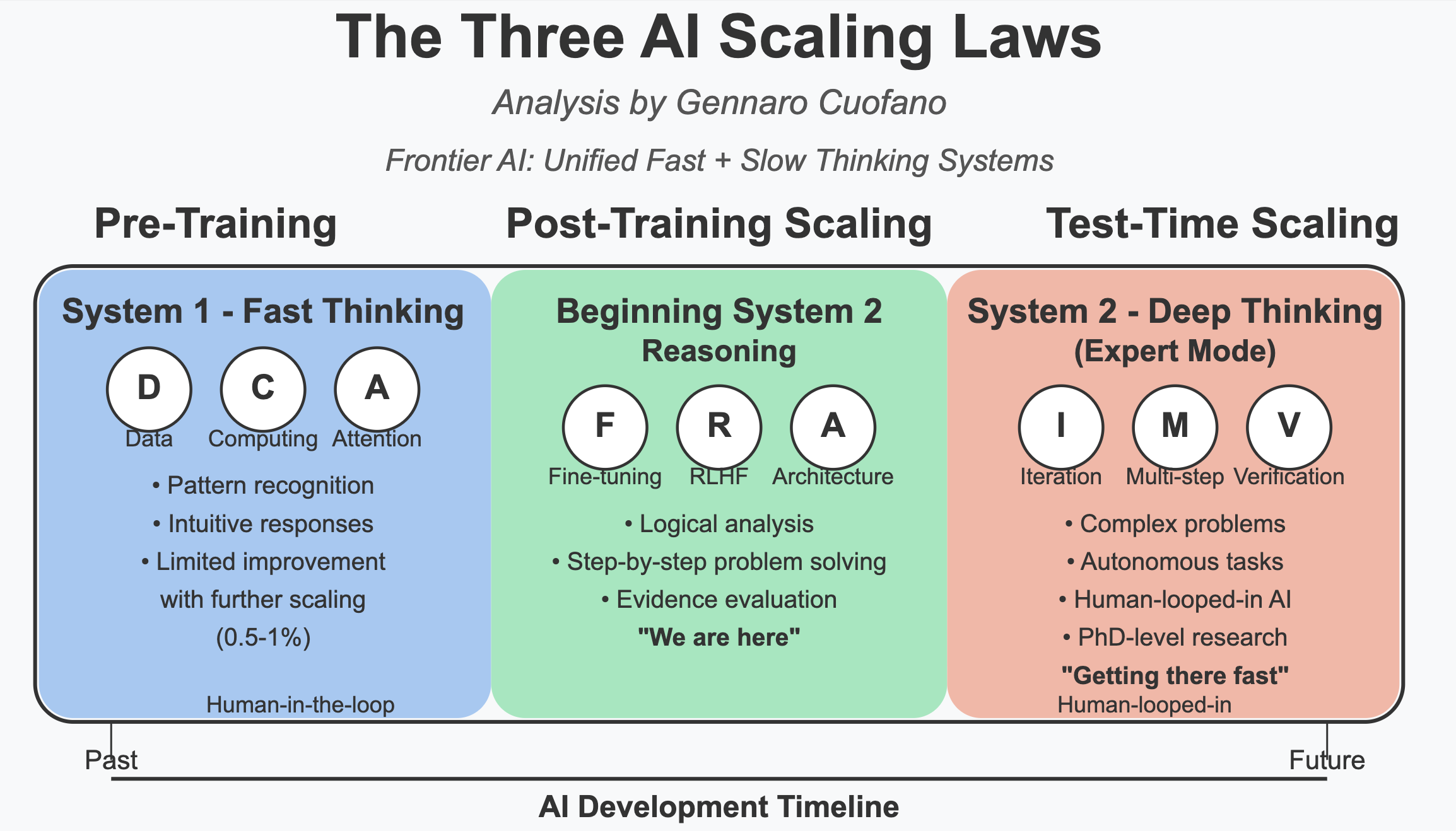
In the three AI scaling laws, I’ve highlighted how AI is scaling through:
-
Pre-training scaling refers to the traditional method of scaling large language models (LLMs) by increasing data, computing power, and refining attention-based algorithms. This scaling law has driven AI progress over the past decade, but its improvements have started to plateau.
-
Post-training scaling involves fine-tuning and optimizing pre-trained models through additional training techniques, including reinforcement learning and architectural enhancements. This enables AI to go beyond simple pattern recognition and start reasoning more effectively.
-
Test-Time Scaling (Long Thinking) – This is the newest phase of scaling, where AI inference is enhanced through iterative multi-step reasoning. Instead of relying on a single-shot response, AI models perform multiple reasoning steps at inference time, significantly improving their ability to tackle complex problems.
Each scaling paradigm is driving AI development up and to the right.
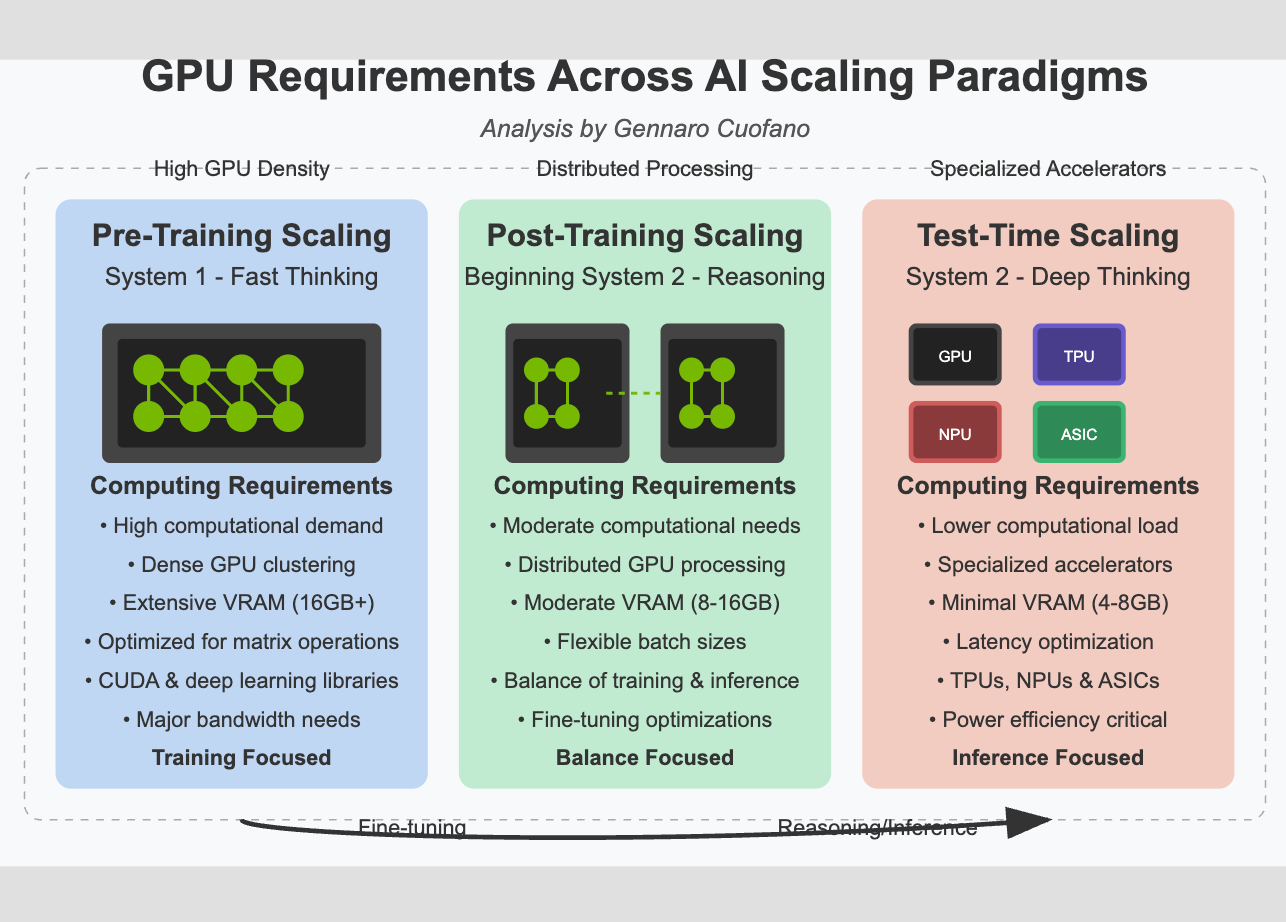
However, this also creates an industry around each scaling paradigm with different computing (GPU) requirements.
The transition across these three scaling paradigms isn’t just a theoretical evolution—it requires fundamentally different computing architectures.
As AI systems advance through these paradigms, their computational requirements evolve dramatically.
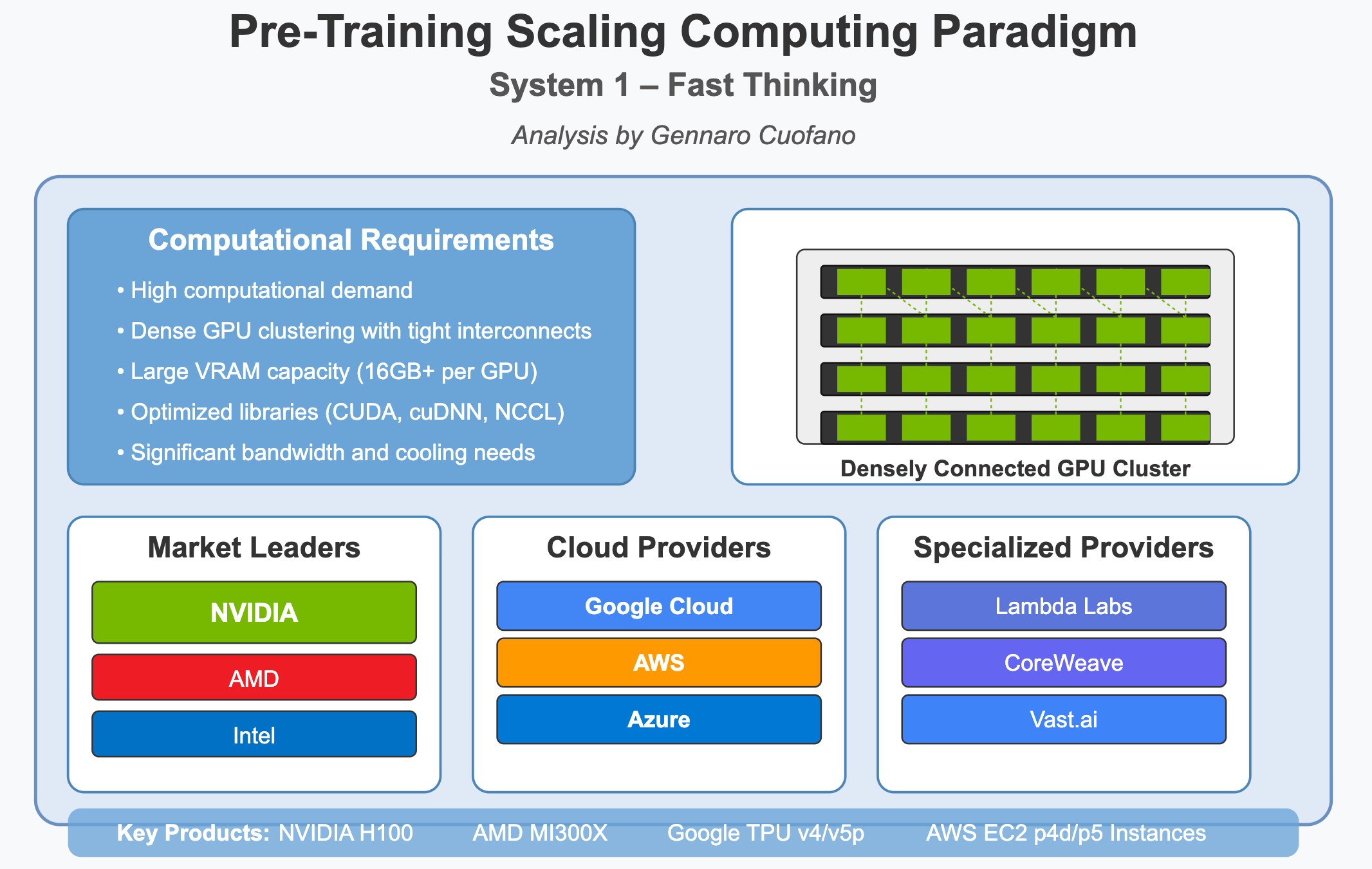
The pre-training phase demands the most intense computational resources:
-
High computational demand: Requires massive parallel processing capabilities
-
Dense GPU clustering: GPUs must be tightly interconnected with high-bandwidth connections
-
Extensive VRAM: Typically 16 GB+ per GPU to handle large models and datasets
-
Optimized libraries: Reliance on CUDA and specialized deep learning libraries
-
Major bandwidth needs: Moving enormous amounts of data between memory and processing units
Organizations like OpenAI and Google have invested in supercomputer-level infrastructure with thousands of interconnected GPUs to handle this phase.
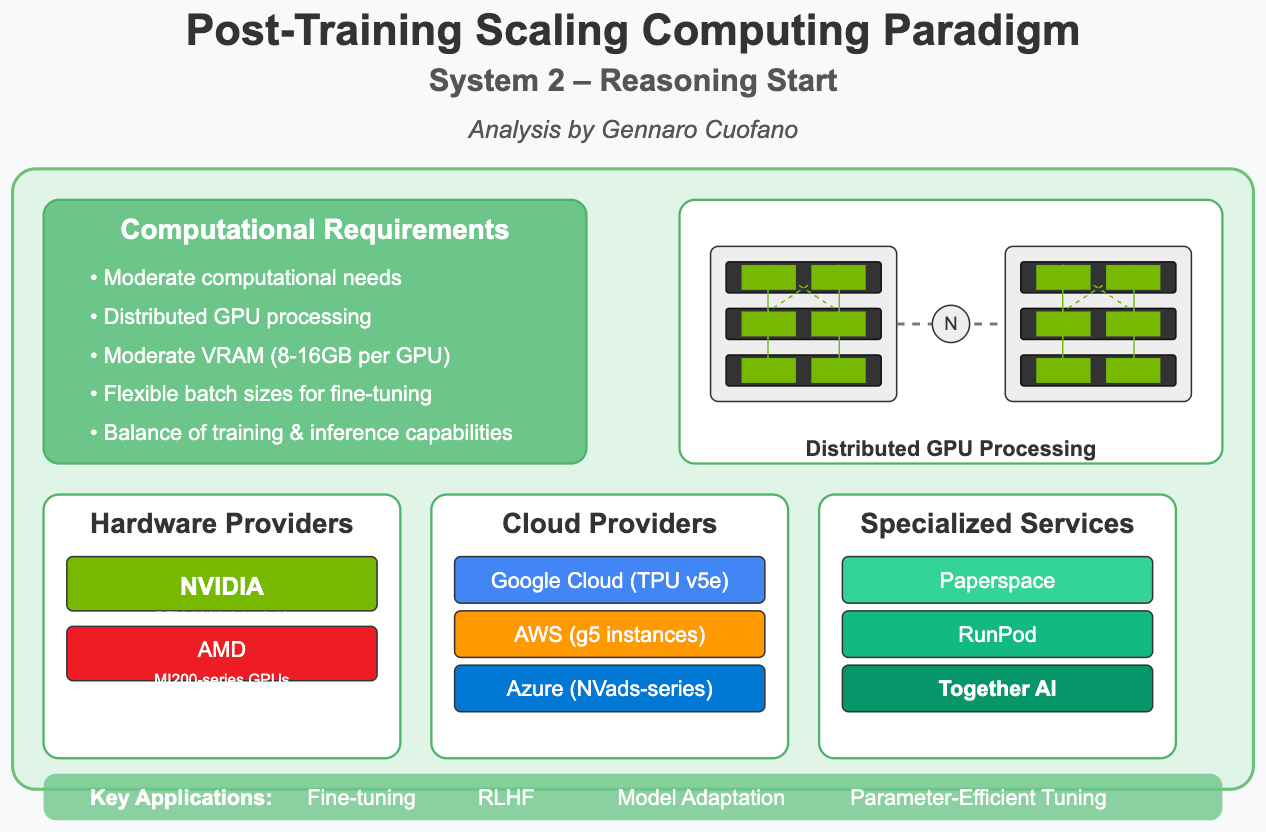
As we move to the fine-tuning and reasoning enhancement stage, the computing requirements shift:
-
Moderate computational needs: Less intensive than pre-training but still substantial
-
Distributed GPU processing: More flexible GPU arrangements with fewer tight interconnections
-
Moderate VRAM: Typically 8-16GB per GPU, allowing for more accessibility
-
Flexible batch sizes: Smaller datasets enable more efficient processing patterns
-
Balance of training & inference: Systems must handle both aspects effectively
This represents our current state, in which companies are building more distributed systems to handle continued training and increase inference loads.
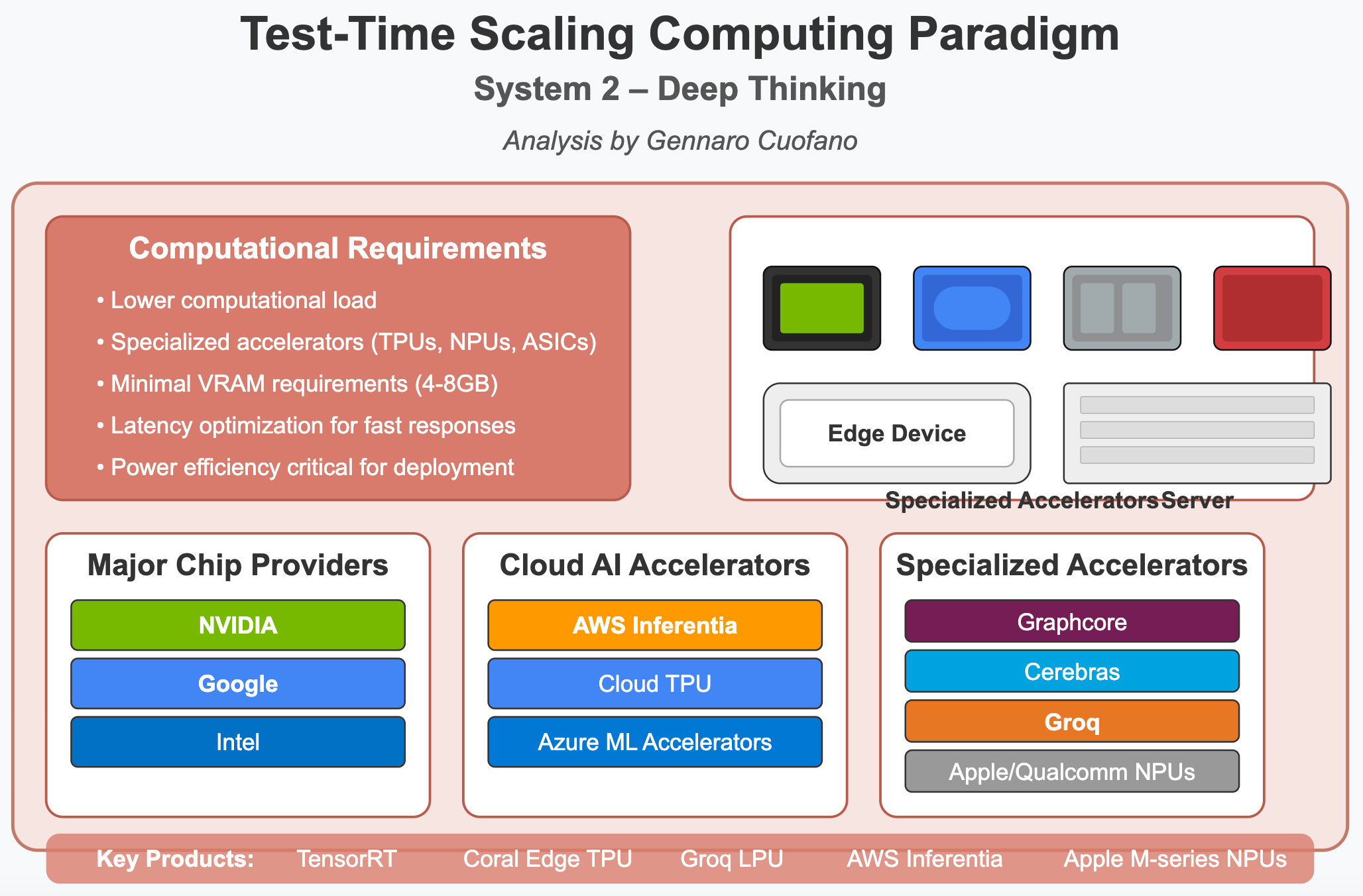
The future of AI computing for deep reasoning will leverage more diverse hardware:
-
Lower computational load: Individual operations require less raw computing power
-
Specialized accelerators: Purpose-built hardware like TPUs, NPUs, and custom ASICs
-
Minimal VRAM: Often, 4-8GB is sufficient for inference tasks
-
Latency optimization: Focus on quick response times rather than massive throughput
-
Power efficiency: Critical for deploying AI at scale in various environments
This evolution explains why many hyperscalers are reorganizing their companies around AI.
For instance, AWS CEO Matt Garman recently stated that Agentic AI applied to e-commerce could be “the next multibillion-dollar business for AWS.”
Similarly, OpenAI projects that one-third of its 2025 revenue will come from SoftBank’s spending on Agentic AI tools.
This computing infrastructure is enabling the following shift.
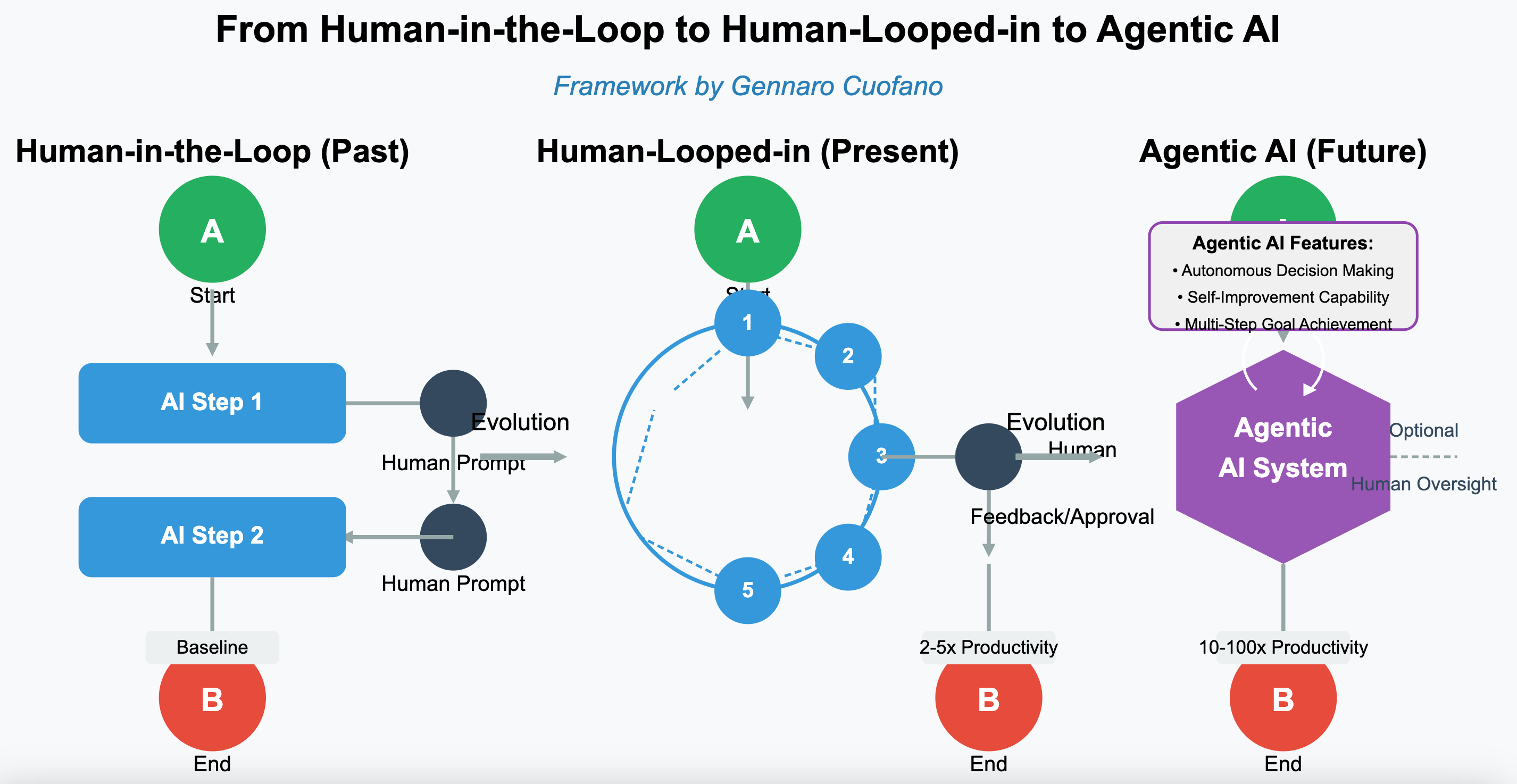
-
Human-in-the-Loop (Past): Humans operate AI tools step-by-step; modest productivity gains
-
Human-Looped-in (Present): AI handles many steps; humans guide and refine; 2–5x productivity gains
-
Agentic AI (Future): AI autonomously plans, executes, and adapts with minimal human input; 10–100x productivity multipliers
This represents a fundamental shift in the AI paradigm—from systems that require continuous human guidance to systems that operate autonomously and only engage humans when necessary.
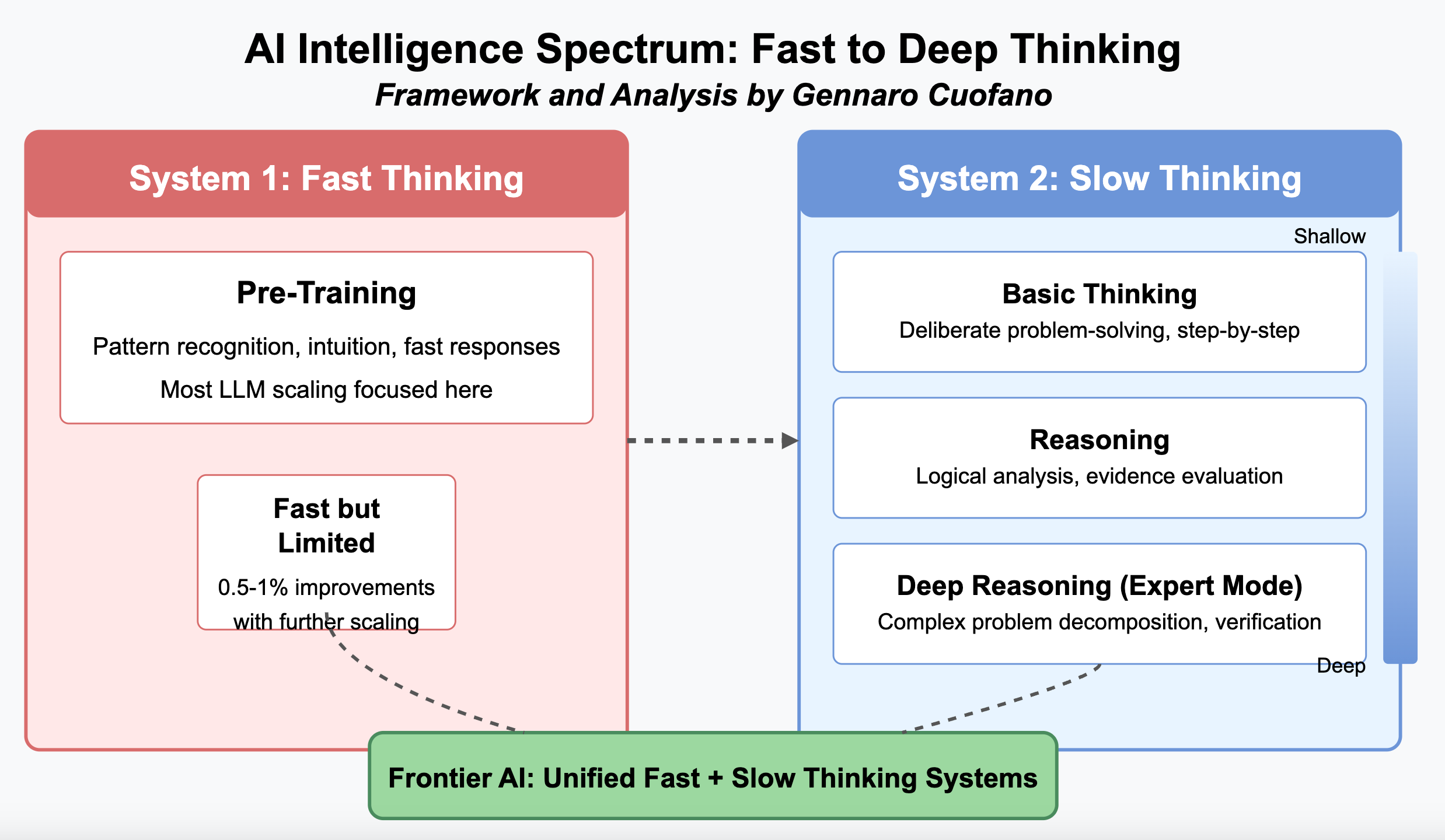
The frontier of AI development is moving toward a unified vision where we won’t necessarily have separate System 1-like or System 2-like models.
Instead, we’ll have integrated systems that tap into fast and slow thinking capabilities.
This unified approach aims to:
-
Leverage the strengths of both fast and slow thinking systems
-
Provide more comprehensive intelligence capabilities
-
Enable seamless transitions between quick responses and deep reasoning
-
Support more natural human-AI collaboration
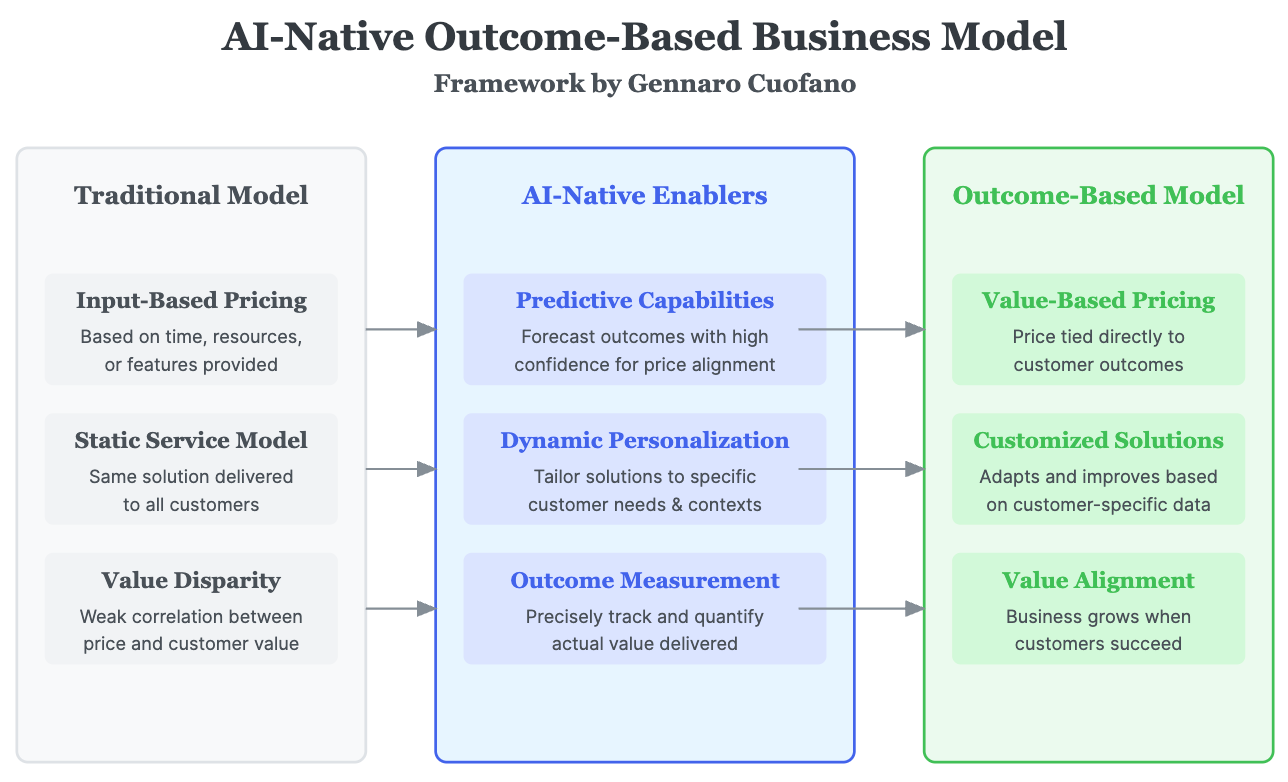
This technological evolution is driving profound changes in AI business models. Traditional software models rely on license, subscription, or usage-based fees.
However, AI-first companies are shifting toward outcome-based payment structures:
-
Companies pay only for measurable results rather than time or usage
-
Services align directly with business success metrics
-
Enterprise AI sales transform from software contracts to AI-driven business architecture
-
Pre-Training: High-Density GPU Clusters
-
Extreme compute demands
-
Requires tightly coupled GPU clusters, high VRAM, and massive bandwidth
-
Infrastructure investments by OpenAI, Google, etc.
-
-
Post-Training: Distributed GPU Systems
-
Moderate compute intensity
-
Flexible distributed architectures
-
Balanced needs for training and inference
-
-
Test-Time: Specialized Inference Accelerators
-
Lower per-operation compute demand
-
Emphasis on latency and power efficiency
-
Uses specialized chips (TPUs, NPUs, ASICs)
-
-
Shift from traditional software pricing (license, subscription, usage) to outcome-based models
-
Enterprises pay based on measurable results
-
AI becomes integrated into business architecture, not just software tooling
-
Reflects a deeper alignment between AI services and business value
With massive ♥️ Gennaro Cuofano, The Business Engineer
This is part of an Enterprise AI series to tackle many of the day-to-day challenges you might face as a professional, executive, founder, or investor in the current AI landscape.







