Agentic AI Systems are all the rage these days! They are simply LLMs in a for-loop connected with certain prompts and tools which can autonomously do tasks for you. However, you can also build reliable step-by-step workflows, guiding the LLM to be more reliable as it solves problems for you. Recently in February 2025, OpenAI launched Deep Research, which is an agent which can take a user topic, automatically run a bunch of searches and compile them into a nice report. However, it is only available in their 200$ pro plan. Here I will show you a hands-on step-by-step guide on how to build your own Deep Research and Report Generation Agent for less than a dollar using LangGraph!
Brief on Deep Research by OpenAI
OpenAI launched Deep Research on February 2, 2025, where it has been launched as an additional capability in their ChatGPT product. They call this a new agentic capability that can do multi-step research on the internet for complex tasks or queries given by the user. What they claim is that it accomplishes in tens of minutes what would take a human many hours.

Deep research is OpenAI’s current Agentic AI product that can do work for you autonomously. You give it a task or topic via a prompt, and ChatGPT will find, analyze, and synthesize hundreds of online sources to create a comprehensive report at the level of a research analyst. Powered by a version of the upcoming OpenAI o3 model that’s optimized for web browsing and data analysis, it leverages reasoning to search, interpret, and analyze massive amounts of text, images, and PDFs on the internet, to finally compile a nice structured report.
This does come however with some restrictions as you can only use it if you have the 200$ ChatGPT pro subscription. That is where I come in with my own Agentic AI System which can do deep research and build a nice compiled report in less than a dollar. Let’s get started!
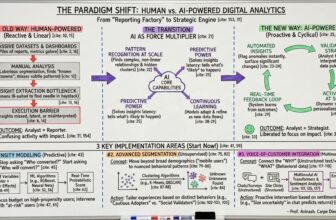
Deep Research & Structured Report Generation Planning Agentic AI System Architecture
The following figure shows the overall architecture of our system which we will be implementing with LangChain’s LangGraph open-source framework for building stateful agentic systems with ease and control.
The key components which will power the above system include:
- A powerful Large Language Model which is good in reasoning. We are using GPT-4o which is not super expensive and fast, however, you can even use LLMs like Llama 3.2 or other open-source alternatives.
- LangGraph for building our agentic system as it is an excellent framework for building cyclical graph-based systems which can maintain state variables throughout the workflow and help build agentic feedback loops easily.
- Tavily AI is an excellent AI-powered search engine, perfect for web research and getting data from websites to power our Deep Research System.
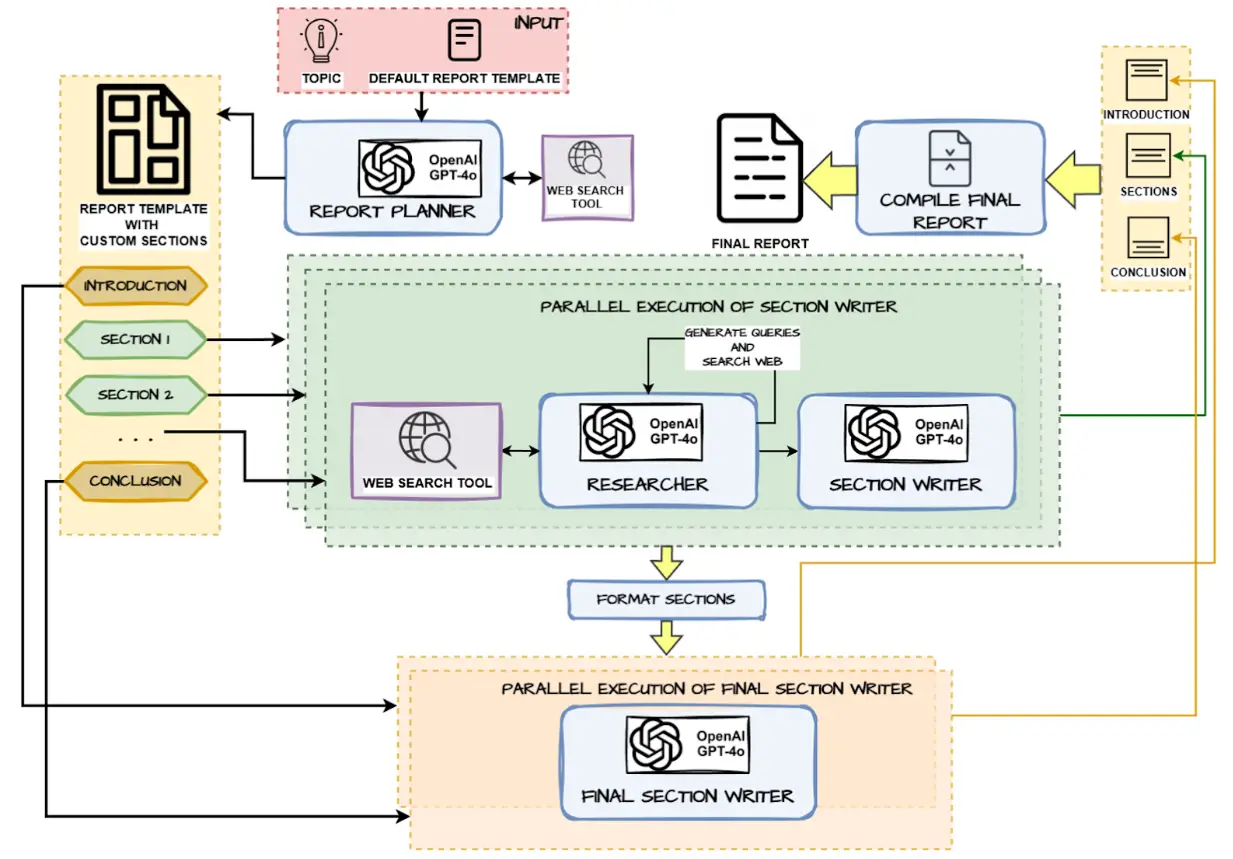
This project focuses on building a Planning Agent for Deep Research and Structured Report Generation as an alternative to OpenAI’s Deep Research. The agent follows the popular Planning Agent Design Pattern and automates the process of analyzing a user-defined topic, performing deep web research, and generating a well-structured report. The workflow is actually inspired by LangChain’s own Report mAIstro so full credit to them for coming up with the workflow, I took that as my baseline inspiration and then built out this system, which includes the following components:
1. Report Planning:
- The agent analyzes the user-provided topic and default report template to create a custom plan for the report.
- Sections such as Introduction, Key Sections, and Conclusion are defined based on the topic.
- A web search tool is used to collect the information required before deciding on the main sections.
2. Parallel Execution for Research and Writing:
- The agent uses parallel execution to efficiently perform:
- Web Research: Queries are generated for each section and executed via the web search tool to retrieve up-to-date information.
- Section Writing: The retrieved data is used to write content for each section, with the following process:
- The Researcher gathers relevant data from the web.
- The Section Writer uses the data to generate structured content for the assigned section.
3. Formatting Completed Sections:
- Once all sections are written, they are formatted to ensure consistency and adherence to the report structure.
4. Introduction and Conclusion Writing:
- After the main sections are completed and formatted:
- The Introduction and Conclusion are written based on the content of the remaining sections (in parallel)
- This process ensures that these sections align with the overall flow and insights of the report.
5. Final Compilation:
- All completed sections are compiled together to generate the final report.
- The final output is a comprehensive and structured report in the style of Wiki docs.
Let’s now start building out these components step-by-step with LangGraph and Tavily.
Hands-on Implementation of our Deep Research & Structured Report Generation Planning Agentic AI System
We will now implement the end-to-end workflow for our Deep Research Report Generator Agentic AI System based on the architecture we discussed in detail in the previous section step-by-step with detailed explanations, code and outputs.
Install Dependencies
We start by installing the necessary dependencies which are going to be the libraries we will be using to build our system. This includes langchain, LangGraph and also rich for generating nice markdown reports.
!pip install langchain==0.3.14
!pip install langchain-openai==0.3.0
!pip install langchain-community==0.3.14
!pip install langgraph==0.2.64
!pip install richEnter Open AI API Key
We enter our Open AI key using the getpass() function so we don’t accidentally expose our key in the code.
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')Enter Tavily Search API Key
We enter our Tavily Search key using the getpass() function so we don’t accidentally expose our key in the code. You can get the key from here and they have a generous free tier.
TAVILY_API_KEY = getpass('Enter Tavily Search API Key: ')Setup Environment Variables
Next, we set up some system environment variables which will be used later when authenticating our LLM and Tavily Search.
import os
os.environ['OPENAI_API_KEY'] = OPENAI_KEY
os.environ['TAVILY_API_KEY'] = TAVILY_API_KEYDefine Agent State Schema
We use LangGraph to build our agentic system as a graph with nodes where each node consists of a specific execution step in the overall workflow. Each specific set of operations (nodes) will have their own schema as defined below. You can customize this further based on your own style of report generation.
from typing_extensions import TypedDict
from pydantic import BaseModel, Field
import operator
from typing import Annotated, List, Optional, Literal
# defines structure for each section in the report
class Section(BaseModel):
name: str = Field(
description="Name for a particular section of the report.",
)
description: str = Field(
description="Brief overview of the main topics and concepts to be covered in this section.",
)
research: bool = Field(
description="Whether to perform web search for this section of the report."
)
content: str = Field(
description="The content for this section."
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="All the Sections of the overall report.",
)
# defines structure for queries generated for deep research
class SearchQuery(BaseModel):
search_query: str = Field(None, description="Query for web search.")
class Queries(BaseModel):
queries: List[SearchQuery] = Field(
description="List of web search queries.",
)
# consists of input topic and output report generated
class ReportStateInput(TypedDict):
topic: str # Report topic
class ReportStateOutput(TypedDict):
final_report: str # Final report
# overall agent state which will be passed and updated in nodes in the graph
class ReportState(TypedDict):
topic: str # Report topic
sections: list[Section] # List of report sections
completed_sections: Annotated[list, operator.add] # Send() API
report_sections_from_research: str # completed sections to write final sections
final_report: str # Final report
# defines the key structure for sections written using the agent
class SectionState(TypedDict):
section: Section # Report section
search_queries: list[SearchQuery] # List of search queries
source_str: str # String of formatted source content from web search
report_sections_from_research: str # completed sections to write final sections
completed_sections: list[Section] # Final key in outer state for Send() API
class SectionOutputState(TypedDict):
completed_sections: list[Section] # Final key in outer state for Send() APIUtility Functions
We define a few utility functions which will help us run parallel web search queries and format results obtained from the web.
1. run_search_queries(…)
This will asynchronously run Tavily search queries for a specific list of queries and return back the search results. This is async so it is non-blocking and can be executed in parallel.
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapper
import asyncio
from dataclasses import asdict, dataclass
# just to handle objects created from LLM reponses
@dataclass
class SearchQuery:
search_query: str
def to_dict(self) -> Dict[str, Any]:
return asdict(self)
tavily_search = TavilySearchAPIWrapper()
async def run_search_queries(
search_queries: List[Union[str, SearchQuery]],
num_results: int = 5,
include_raw_content: bool = False
) -> List[Dict]:
search_tasks = []
for query in search_queries:
# Handle both string and SearchQuery objects
# Just in case LLM fails to generate queries as:
# class SearchQuery(BaseModel):
# search_query: str
query_str = query.search_query if isinstance(query, SearchQuery)
else str(query) # text query
try:
# get results from tavily async (in parallel) for each search query
search_tasks.append(
tavily_search.raw_results_async(
query=query_str,
max_results=num_results,
search_depth="advanced",
include_answer=False,
include_raw_content=include_raw_content
)
)
except Exception as e:
print(f"Error creating search task for query '{query_str}': {e}")
continue
# Execute all searches concurrently and await results
try:
if not search_tasks:
return []
search_docs = await asyncio.gather(*search_tasks, return_exceptions=True)
# Filter out any exceptions from the results
valid_results = [
doc for doc in search_docs
if not isinstance(doc, Exception)
]
return valid_results
except Exception as e:
print(f"Error during search queries: {e}")
return []2. format_search_query_results(…)
This will extract the context from Tavily search results, make sure content is not duplicated from the same URLs and format it to show the Source, URL, and relevant content (and optionally raw content which can be truncated based on the number of tokens)
import tiktoken
from typing import List, Dict, Union, Any
def format_search_query_results(
search_response: Union[Dict[str, Any], List[Any]],
max_tokens: int = 2000,
include_raw_content: bool = False
) -> str:
encoding = tiktoken.encoding_for_model("gpt-4")
sources_list = []
# Handle different response formats if search results is a dict
if isinstance(search_response, dict):
if 'results' in search_response:
sources_list.extend(search_response['results'])
else:
sources_list.append(search_response)
# if search results is a list
elif isinstance(search_response, list):
for response in search_response:
if isinstance(response, dict):
if 'results' in response:
sources_list.extend(response['results'])
else:
sources_list.append(response)
elif isinstance(response, list):
sources_list.extend(response)
if not sources_list:
return "No search results found."
# Deduplicate by URL and keep unique sources (website urls)
unique_sources = {}
for source in sources_list:
if isinstance(source, dict) and 'url' in source:
if source['url'] not in unique_sources:
unique_sources[source['url']] = source
# Format output
formatted_text = "Content from web search:\n\n"
for i, source in enumerate(unique_sources.values(), 1):
formatted_text += f"Source {source.get('title', 'Untitled')}:\n===\n"
formatted_text += f"URL: {source['url']}\n===\n"
formatted_text += f"Most relevant content from source: {source.get('content', 'No content available')}\n===\n"
if include_raw_content:
# truncate raw webpage content to a certain number of tokens to prevent exceeding LLM max token window
raw_content = source.get("raw_content", "")
if raw_content:
tokens = encoding.encode(raw_content)
truncated_tokens = tokens[:max_tokens]
truncated_content = encoding.decode(truncated_tokens)
formatted_text += f"Raw Content: {truncated_content}\n\n"
return formatted_text.strip()We can test out these functions just to see if it work as follows:
docs = await run_search_queries(['langgraph'], include_raw_content=True)
output = format_search_query_results(docs, max_tokens=500,
include_raw_content=True)
print(output)Output
Content from web search:Source Introduction - GitHub Pages:
===
URL: https://langchain-ai.github.io/langgraphjs/
===
Most relevant content from source: Overview¶. LangGraph is a library for
building stateful, multi-actor applications with LLMs, used to create agent
and multi-agent workflows......
===
Raw Content: 🦜🕸️LangGraph.js¶
⚡ Building language agents as graphs ⚡
Looking for the Python version? Click
here ( docs).
Overview......Source ️LangGraph - GitHub Pages:
===
URL: https://langchain-ai.github.io/langgraph/
===
Most relevant content from source: Overview¶. LangGraph is a library for
building stateful, multi-actor applications with LLMs, ......
===
Raw Content: 🦜🕸️LangGraph¶
⚡ Building language agents as graphs ⚡
Note
Looking for the JS version? See the JS repo and the JS docs.
Overview¶
LangGraph is a library for building
stateful, multi-actor applications with LLMs, ......
Creating a Default Report Template
This is the starting point for the LLM to get an idea of how to build a general report and it will use this as a guideline to build a custom report structure based on the topic. Remember this is not the final report structure but more of a prompt to guide the agent.
# Structure Guideline
DEFAULT_REPORT_STRUCTURE = """The report structure should focus on breaking-down the user-provided topic
and building a comprehensive report in markdown using the following format:
1. Introduction (no web search needed)
- Brief overview of the topic area
2. Main Body Sections:
- Each section should focus on a sub-topic of the user-provided topic
- Include any key concepts and definitions
- Provide real-world examples or case studies where applicable
3. Conclusion (no web search needed)
- Aim for 1 structural element (either a list of table) that distills the main body sections
- Provide a concise summary of the report
When generating the final response in markdown, if there are special characters in the text,
such as the dollar symbol, ensure they are escaped properly for correct rendering e.g $25.5 should become \$25.5
"""Instruction Prompts for Report Planner
There are two main instruction prompts:
1. REPORT_PLAN_QUERY_GENERATOR_PROMPT
Helps the LLM to generate an initial list of questions based on the topic to get more information from the web about that topic so that it can plan the overall sections and structure of the report
REPORT_PLAN_QUERY_GENERATOR_PROMPT = """You are an expert technical report writer, helping to plan a report.
The report will be focused on the following topic:
{topic}
The report structure will follow these guidelines:
{report_organization}
Your goal is to generate {number_of_queries} search queries that will help gather comprehensive information for planning the report sections.
The query should:
1. Be related to the topic
2. Help satisfy the requirements specified in the report organization
Make the query specific enough to find high-quality, relevant sources while covering the depth and breadth needed for the report structure.
"""2. REPORT_PLAN_SECTION_GENERATOR_PROMPT
Here we feed the LLM with the default report template, the topic name and the search results from the initial queries generated to create a detailed structure for the report. The LLM will generate a structured response of the following fields for each major section which will be in the report (this is just the report structure – no content is created at this step):
- Name – Name for this section of the report.
- Description – Brief overview of the main topics and concepts to be covered in this section.
- Research – Whether to perform web search for this section of the report or not.
- Content – The content of the section, which you will leave blank for now.
REPORT_PLAN_SECTION_GENERATOR_PROMPT = """You are an expert technical report writer, helping to plan a report.
Your goal is to generate the outline of the sections of the report.
The overall topic of the report is:
{topic}
The report should follow this organizational structure:
{report_organization}
You should reflect on this additional context information from web searches to plan the main sections of the report:
{search_context}
Now, generate the sections of the report. Each section should have the following fields:
- Name - Name for this section of the report.
- Description - Brief overview of the main topics and concepts to be covered in this section.
- Research - Whether to perform web search for this section of the report or not.
- Content - The content of the section, which you will leave blank for now.
Consider which sections require web search.
For example, introduction and conclusion will not require research because they will distill information from other parts of the report.
"""Node Function for Report Planner
We will build the logic for the report planner node which has the objective of creating a structured custom report template with major section names and descriptions based on the input user topic and the default report template guidelines.
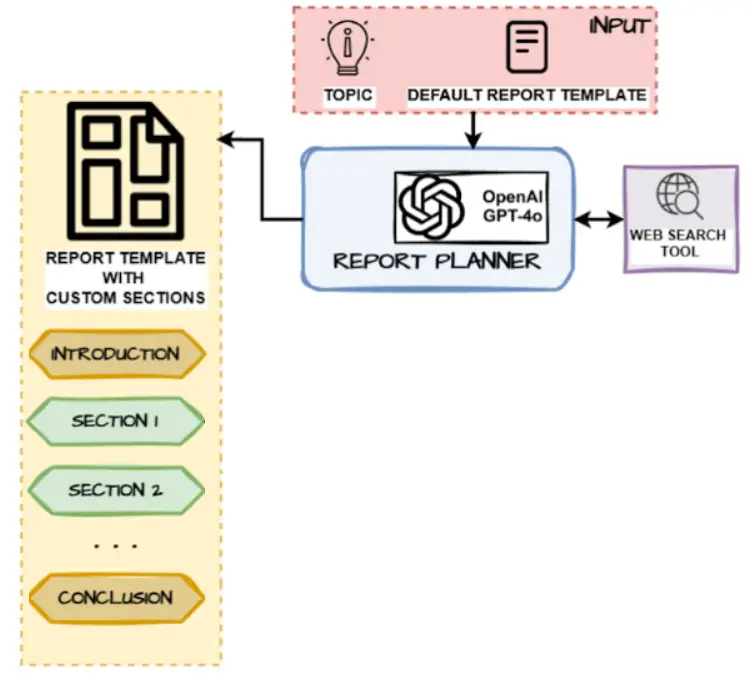
This function uses the two prompts created earlier to:
- First, generate some queries based on the user topic
- Search the web and get some information on these queries
- Use this information to generate the overall structure of the report with the key sections necessary to be created
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
async def generate_report_plan(state: ReportState):
"""Generate the overall plan for building the report"""
topic = state["topic"]
print('--- Generating Report Plan ---')
report_structure = DEFAULT_REPORT_STRUCTURE
number_of_queries = 8
structured_llm = llm.with_structured_output(Queries)
system_instructions_query = REPORT_PLAN_QUERY_GENERATOR_PROMPT.format(
topic=topic,
report_organization=report_structure,
number_of_queries=number_of_queries
)
try:
# Generate queries
results = structured_llm.invoke([
SystemMessage(content=system_instructions_query),
HumanMessage(content="Generate search queries that will help with planning the sections of the report.")
])
# Convert SearchQuery objects to strings
query_list = [
query.search_query if isinstance(query, SearchQuery) else str(query)
for query in results.queries
]
# Search web and ensure we wait for results
search_docs = await run_search_queries(
query_list,
num_results=5,
include_raw_content=False
)
if not search_docs:
print("Warning: No search results returned")
search_context = "No search results available."
else:
search_context = format_search_query_results(
search_docs,
include_raw_content=False
)
# Generate sections
system_instructions_sections = REPORT_PLAN_SECTION_GENERATOR_PROMPT.format(
topic=topic,
report_organization=report_structure,
search_context=search_context
)
structured_llm = llm.with_structured_output(Sections)
report_sections = structured_llm.invoke([
SystemMessage(content=system_instructions_sections),
HumanMessage(content="Generate the sections of the report. Your response must include a 'sections' field containing a list of sections. Each section must have: name, description, plan, research, and content fields.")
])
print('--- Generating Report Plan Completed ---')
return {"sections": report_sections.sections}
except Exception as e:
print(f"Error in generate_report_plan: {e}")
return {"sections": []}Instruction Prompts for Section Builder – Query Generator
There is one main instruction prompt:
1. REPORT_SECTION_QUERY_GENERATOR_PROMPT
Helps the LLM to generate a comprehensive list of questions for the topic of that specific section which needs to be built
REPORT_SECTION_QUERY_GENERATOR_PROMPT = """Your goal is to generate targeted web search queries that will gather comprehensive information for writing a technical report section.
Topic for this section:
{section_topic}
When generating {number_of_queries} search queries, ensure that they:
1. Cover different aspects of the topic (e.g., core features, real-world applications, technical architecture)
2. Include specific technical terms related to the topic
3. Target recent information by including year markers where relevant (e.g., "2024")
4. Look for comparisons or differentiators from similar technologies/approaches
5. Search for both official documentation and practical implementation examples
Your queries should be:
- Specific enough to avoid generic results
- Technical enough to capture detailed implementation information
- Diverse enough to cover all aspects of the section plan
- Focused on authoritative sources (documentation, technical blogs, academic papers)"""
Node Function for Section Builder – Generate Queries (Query Generator)
This uses the section topic and the instruction prompt above to generate some questions for researching on the web to get useful information on the section topic.
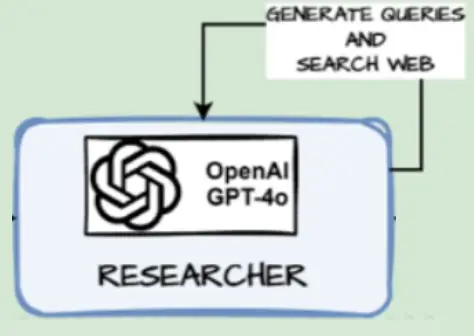
def generate_queries(state: SectionState):
""" Generate search queries for a specific report section """
# Get state
section = state["section"]
print('--- Generating Search Queries for Section: '+ section.name +' ---')
# Get configuration
number_of_queries = 5
# Generate queries
structured_llm = llm.with_structured_output(Queries)
# Format system instructions
system_instructions = REPORT_SECTION_QUERY_GENERATOR_PROMPT.format(section_topic=section.description, number_of_queries=number_of_queries)
# Generate queries
user_instruction = "Generate search queries on the provided topic."
search_queries = structured_llm.invoke([SystemMessage(content=system_instructions),
HumanMessage(content=user_instruction)])
print('--- Generating Search Queries for Section: '+ section.name +' Completed ---')
return {"search_queries": search_queries.queries}Node Function for Section Builder – Search Web
Takes the queries generated by generate_queries(…)for a specific section, searches the web and formats the search results using the utility functions we defined earlier.
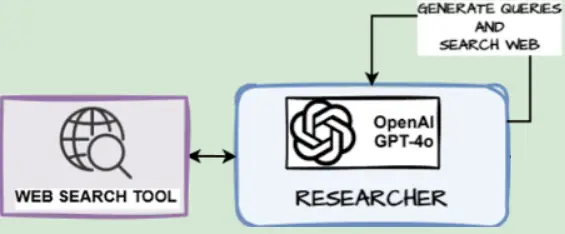
async def search_web(state: SectionState):
""" Search the web for each query, then return a list of raw sources and a formatted string of sources."""
# Get state
search_queries = state["search_queries"]
print('--- Searching Web for Queries ---')
# Web search
query_list = [query.search_query for query in search_queries]
search_docs = await run_search_queries(search_queries, num_results=6, include_raw_content=True)
# Deduplicate and format sources
search_context = format_search_query_results(search_docs, max_tokens=4000, include_raw_content=True)
print('--- Searching Web for Queries Completed ---')
return {"source_str": search_context}Instruction Prompts for Section Builder – Section Writer
There is one main instruction prompt:
1. SECTION_WRITER_PROMPT
Constrains the LLM to generate and write the content for a specific section using certain guidelines on style, structure, length, approach and the documents obtained from the web earlier using the search_web(…) function are also sent.
SECTION_WRITER_PROMPT = """You are an expert technical writer crafting one specific section of a technical report.
Title for the section:
{section_title}
Topic for this section:
{section_topic}
Guidelines for writing:
1. Technical Accuracy:
- Include specific version numbers
- Reference concrete metrics/benchmarks
- Cite official documentation
- Use technical terminology precisely
2. Length and Style:
- Strict 150-200 word limit
- No marketing language
- Technical focus
- Write in simple, clear language do not use complex words unnecessarily
- Start with your most important insight in **bold**
- Use short paragraphs (2-3 sentences max)
3. Structure:
- Use ## for section title (Markdown format)
- Only use ONE structural element IF it helps clarify your point:
* Either a focused table comparing 2-3 key items (using Markdown table syntax)
* Or a short list (3-5 items) using proper Markdown list syntax:
- Use `*` or `-` for unordered lists
- Use `1.` for ordered lists
- Ensure proper indentation and spacing
- End with ### Sources that references the below source material formatted as:
* List each source with title, date, and URL
* Format: `- Title : URL`
3. Writing Approach:
- Include at least one specific example or case study if available
- Use concrete details over general statements
- Make every word count
- No preamble prior to creating the section content
- Focus on your single most important point
4. Use this source material obtained from web searches to help write the section:
{context}
5. Quality Checks:
- Format should be Markdown
- Exactly 150-200 words (excluding title and sources)
- Careful use of only ONE structural element (table or bullet list) and only if it helps clarify your point
- One specific example / case study if available
- Starts with bold insight
- No preamble prior to creating the section content
- Sources cited at end
- If there are special characters in the text, such as the dollar symbol,
ensure they are escaped properly for correct rendering e.g $25.5 should become \$25.5
"""Node Function for Section Builder – Write Section (Section Writer)
Uses the SECTION_WRITER_PROMPT from above and feeds it with the section name, description and web search documents and passes it to an LLM to write the content for that section
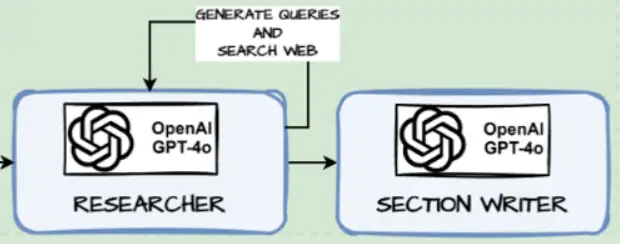
def write_section(state: SectionState):
""" Write a section of the report """
# Get state
section = state["section"]
source_str = state["source_str"]
print('--- Writing Section : '+ section.name +' ---')
# Format system instructions
system_instructions = SECTION_WRITER_PROMPT.format(section_title=section.name, section_topic=section.description, context=source_str)
# Generate section
user_instruction = "Generate a report section based on the provided sources."
section_content = llm.invoke([SystemMessage(content=system_instructions),
HumanMessage(content=user_instruction)])
# Write content to the section object
section.content = section_content.content
print('--- Writing Section : '+ section.name +' Completed ---')
# Write the updated section to completed sections
return {"completed_sections": [section]}Create the Section Builder Sub-Agent
This agent (or to be more specific, sub-agent) will be called several times in parallel, once for each section to search the web, get content and then write up that specific section. We leverage LangGraph’s Send construct for doing this.
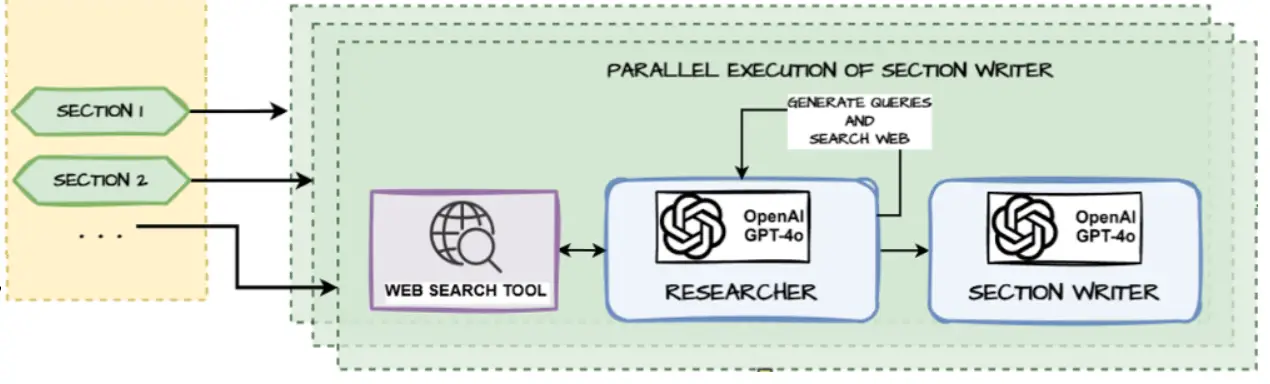
from langgraph.graph import StateGraph, START, END
# Add nodes and edges
section_builder = StateGraph(SectionState, output=SectionOutputState)
section_builder.add_node("generate_queries", generate_queries)
section_builder.add_node("search_web", search_web)
section_builder.add_node("write_section", write_section)
section_builder.add_edge(START, "generate_queries")
section_builder.add_edge("generate_queries", "search_web")
section_builder.add_edge("search_web", "write_section")
section_builder.add_edge("write_section", END)
section_builder_subagent = section_builder.compile()
# Display the graph
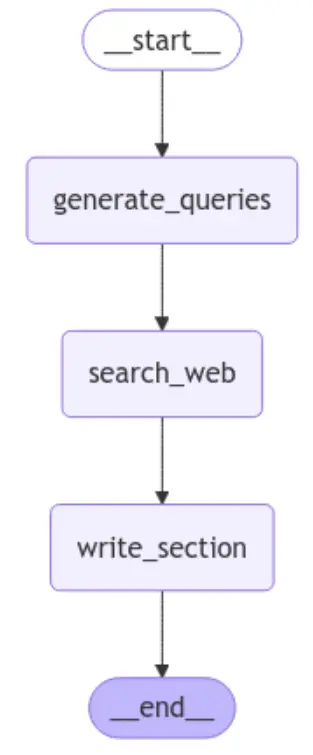
from IPython.display import display, Image
Image(section_builder_subagent.get_graph().draw_mermaid_png())
Output
Create Dynamic Parallelization Node Function – Parallelize Section Writing
Send(…) is used to parallelize and call the section_builder_subagent once for each section to write up the content (in parallel)
from langgraph.constants import Send
def parallelize_section_writing(state: ReportState):
""" This is the "map" step when we kick off web research for some sections of the report in parallel and then write the section"""
# Kick off section writing in parallel via Send() API for any sections that require research
return [
Send("section_builder_with_web_search", # name of the subagent node
{"section": s})
for s in state["sections"]
if s.research
]Create Format Sections Node Function
This is basically the section where all the sections are formatted and combined together into one big document.
def format_sections(sections: list[Section]) -> str:
""" Format a list of report sections into a single text string """
formatted_str = ""
for idx, section in enumerate(sections, 1):
formatted_str += f"""
{'='*60}
Section {idx}: {section.name}
{'='*60}
Description:
{section.description}
Requires Research:
{section.research}
Content:
{section.content if section.content else '[Not yet written]'}
"""
return formatted_str
def format_completed_sections(state: ReportState):
""" Gather completed sections from research and format them as context for writing the final sections """
print('--- Formatting Completed Sections ---')
# List of completed sections
completed_sections = state["completed_sections"]
# Format completed section to str to use as context for final sections
completed_report_sections = format_sections(completed_sections)
print('--- Formatting Completed Sections is Done ---')
return {"report_sections_from_research": completed_report_sections}Instruction Prompts for the Final Section
There is one main instruction prompt:
1. FINAL_SECTION_WRITER_PROMPT
Constrains the LLM to generate and write the content for either the introduction OR conclusion using certain guidelines on style, structure, length, approach and the content of the already written sections are also sent.
FINAL_SECTION_WRITER_PROMPT = """You are an expert technical writer crafting a section that synthesizes information from the rest of the report.
Title for the section:
{section_title}
Topic for this section:
{section_topic}
Available report content of already completed sections:
{context}
1. Section-Specific Approach:
For Introduction:
- Use # for report title (Markdown format)
- 50-100 word limit
- Write in simple and clear language
- Focus on the core motivation for the report in 1-2 paragraphs
- Use a clear narrative arc to introduce the report
- Include NO structural elements (no lists or tables)
- No sources section needed
For Conclusion/Summary:
- Use ## for section title (Markdown format)
- 100-150 word limit
- For comparative reports:
* Must include a focused comparison table using Markdown table syntax
* Table should distill insights from the report
* Keep table entries clear and concise
- For non-comparative reports:
* Only use ONE structural element IF it helps distill the points made in the report:
* Either a focused table comparing items present in the report (using Markdown table syntax)
* Or a short list using proper Markdown list syntax:
- Use `*` or `-` for unordered lists
- Use `1.` for ordered lists
- Ensure proper indentation and spacing
- End with specific next steps or implications
- No sources section needed
3. Writing Approach:
- Use concrete details over general statements
- Make every word count
- Focus on your single most important point
4. Quality Checks:
- For introduction: 50-100 word limit, # for report title, no structural elements, no sources section
- For conclusion: 100-150 word limit, ## for section title, only ONE structural element at most, no sources section
- Markdown format
- Do not include word count or any preamble in your response
- If there are special characters in the text, such as the dollar symbol,
ensure they are escaped properly for correct rendering e.g $25.5 should become \$25.5"""Create Write Final Sections Node Function
This function uses the instruction prompt FINAL_SECTION_WRITER_PROMPT mentioned above to write up the introduction and conclusion. This function will be executed in parallel using Send(…) below
def write_final_sections(state: SectionState):
""" Write the final sections of the report, which do not require web search and use the completed sections as context"""
# Get state
section = state["section"]
completed_report_sections = state["report_sections_from_research"]
print('--- Writing Final Section: '+ section.name + ' ---')
# Format system instructions
system_instructions = FINAL_SECTION_WRITER_PROMPT.format(section_title=section.name,
section_topic=section.description,
context=completed_report_sections)
# Generate section
user_instruction = "Craft a report section based on the provided sources."
section_content = llm.invoke([SystemMessage(content=system_instructions),
HumanMessage(content=user_instruction)])
# Write content to section
section.content = section_content.content
print('--- Writing Final Section: '+ section.name + ' Completed ---')
# Write the updated section to completed sections
return {"completed_sections": [section]}Create Dynamic Parallelization Node Function – Parallelize Final Section Writing
Send(…) is used to parallelize and call the write_final_sections once for each of the introduction and conclusion to write up the content (in parallel)
from langgraph.constants import Send
def parallelize_final_section_writing(state: ReportState):
""" Write any final sections using the Send API to parallelize the process """
# Kick off section writing in parallel via Send() API for any sections that do not require research
return [
Send("write_final_sections",
{"section": s, "report_sections_from_research": state["report_sections_from_research"]})
for s in state["sections"]
if not s.research
]Compile Final Report Node Function
This function combines all the sections of the report together and compiles it into the final report document
def compile_final_report(state: ReportState):
""" Compile the final report """
# Get sections
sections = state["sections"]
completed_sections = {s.name: s.content for s in state["completed_sections"]}
print('--- Compiling Final Report ---')
# Update sections with completed content while maintaining original order
for section in sections:
section.content = completed_sections[section.name]
# Compile final report
all_sections = "\n\n".join([s.content for s in sections])
# Escape unescaped $ symbols to display properly in Markdown
formatted_sections = all_sections.replace("\\$", "TEMP_PLACEHOLDER") # Temporarily mark already escaped $
formatted_sections = formatted_sections.replace("$", "\\$") # Escape all $
formatted_sections = formatted_sections.replace("TEMP_PLACEHOLDER", "\\$") # Restore originally escaped $
# Now escaped_sections contains the properly escaped Markdown text
print('--- Compiling Final Report Done ---')
return {"final_report": formatted_sections}Build our Deep Research & Report Writer Agent
We now bring all the defined components and sub-agents together and build our main planning agent.
builder = StateGraph(ReportState, input=ReportStateInput, output=ReportStateOutput)
builder.add_node("generate_report_plan", generate_report_plan)
builder.add_node("section_builder_with_web_search", section_builder_subagent)
builder.add_node("format_completed_sections", format_completed_sections)
builder.add_node("write_final_sections", write_final_sections)
builder.add_node("compile_final_report", compile_final_report)
builder.add_edge(START, "generate_report_plan")
builder.add_conditional_edges("generate_report_plan",
parallelize_section_writing,
["section_builder_with_web_search"])
builder.add_edge("section_builder_with_web_search", "format_completed_sections")
builder.add_conditional_edges("format_completed_sections",
parallelize_final_section_writing,
["write_final_sections"])
builder.add_edge("write_final_sections", "compile_final_report")
builder.add_edge("compile_final_report", END)
reporter_agent = builder.compile()
# view agent structure
display(Image(reporter_agent.get_graph(xray=True).draw_mermaid_png()))Output
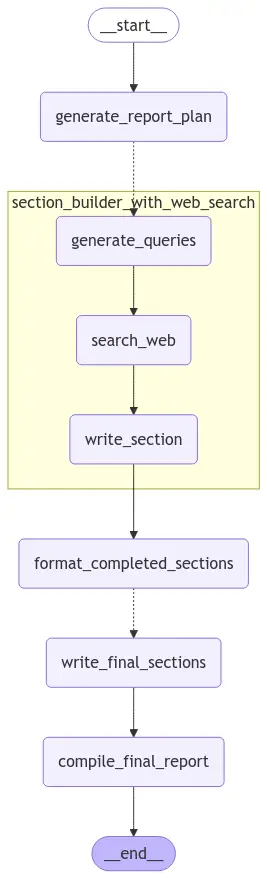
We are now ready to run and test out our agentic system!
Run and Test our Deep Research & Report Writer Agent
Let’s finally put our deep research report writing agent to the test! We will create a simple function to stream the progress live and then show the final report. I would recommend to turn off all the intermediate print messages once you have a functioning agent!
from IPython.display import display
from rich.console import Console
from rich.markdown import Markdown as RichMarkdown
async def call_planner_agent(agent, prompt, config={"recursion_limit": 50}, verbose=False):
events = agent.astream(
{'topic' : prompt},
config,
stream_mode="values",
)
async for event in events:
for k, v in event.items():
if verbose:
if k != "__end__":
display(RichMarkdown(repr(k) + ' -> ' + repr(v)))
if k == 'final_report':
print('='*50)
print('Final Report:')
md = RichMarkdown(v)
display(md)Test Run
topic = "Detailed report on how is NVIDIA winning the game against its competitors"
await call_planner_agent(agent=reporter_agent,
prompt=topic)Output
--- Generating Report Plan ---
--- Generating Report Plan Completed ---
--- Generating Search Queries for Section: NVIDIA's Market Dominance in GPUs
------ Generating Search Queries for Section: Strategic Acquisitions and
Partnerships ---
--- Generating Search Queries for Section: Technological Innovations and AI
Leadership ------ Generating Search Queries for Section: Financial Performance and Growth
Strategy ---
--- Generating Search Queries for Section: NVIDIA's Market Dominance in GPUs
Completed ---
--- Searching Web for Queries ---
--- Generating Search Queries for Section: Financial Performance and Growth
Strategy Completed ---
--- Searching Web for Queries ---
--- Generating Search Queries for Section: Technological Innovations and AI
Leadership Completed ---
--- Searching Web for Queries ---
--- Generating Search Queries for Section: Strategic Acquisitions and
Partnerships Completed ---
--- Searching Web for Queries ---
--- Searching Web for Queries Completed ---
--- Writing Section : Strategic Acquisitions and Partnerships ---
--- Searching Web for Queries Completed ---
--- Writing Section : Financial Performance and Growth Strategy ---
--- Searching Web for Queries Completed ---
--- Writing Section : NVIDIA's Market Dominance in GPUs ---
--- Searching Web for Queries Completed ---
--- Writing Section : Technological Innovations and AI Leadership ---
--- Writing Section : Strategic Acquisitions and Partnerships Completed ---
--- Writing Section : Financial Performance and Growth Strategy Completed ---
--- Writing Section : NVIDIA's Market Dominance in GPUs Completed ---
--- Writing Section : Technological Innovations and AI Leadership Completed ---
--- Formatting Completed Sections ---
--- Formatting Completed Sections is Done ---
--- Writing Final Section: Introduction ------ Writing Final Section:
Conclusion ------ Writing Final Section: Introduction Completed ---
--- Writing Final Section: Conclusion Completed ---
--- Compiling Final Report ---
--- Compiling Final Report Done ---
==================================================
Final Report:
It gives us a pretty comprehensive, well-researched and well-structured report for our given topic as seen above!
Conclusion
If you are reading this, I commend your efforts in staying right till the end in this massive guide! Here we saw that it is not too difficult to build something similar to a full-fledged commercial (and not too cheap at that!) product launched by OpenAI, a company which definitely knows how to push out quality products on Generative AI and now Agentic AI.
We saw a detailed architecture and workflow on how to build our own Deep Research and Report Generation Agentic AI System and overall to run this system, it costs you less than a dollar as promised! If you use open-source components for everything, it is totally free! Plus this is totally customizable where you can control the way the searches happen, the structure, length and style of the report. Do note that if you are using Tavily, you can easily end up making a lot of searches when running this agent for deep research so be mindful and keep track of your usage. This just gives you a foundation to build on and feel free to use this code and system and customize it and make it even better!
Head of Community, Principal AI Scientist at Analytics Vidhya, Published Author and AI Advisor with over 10 years of global experience working with Fortune 100 companies, startups and academic organizations