A few years ago, I fell into the world of anime from which I’d never escape. As my watchlist was growing thinner and thinner, finding the next best anime became harder and harder. There are so many hidden gems out there, but how do I discover them? That’s when I thought—why not let Machine Learning sensei do the hard work? Sounds exciting, right?
In our digital era, recommendation systems are the silent entertainment heroes that power our daily online experiences. Whether it involves suggesting television series, creating a personalized music playlist, or recommending products based on browsing history, these algorithms operate in the background to improve user engagement.
This guide walks you through building a production-ready anime recommendation engine that runs 24/7 without the need for traditional cloud platforms. With hands-on use cases, code snippets, and a detailed exploration of the architecture, you’ll be equipped to build and deploy your own recommendation engine.
Learning Objectives
- Understand the entire data processing and model training workflows to ensure efficiency and scalability.
- Build and deploy an engaging user-friendly recommendation system on Hugging Face Spaces with a dynamic interface.
- Gain hands-on experience in developing end-to-end recommendation engines using machine learning approaches such as SVD, collaborative filtering and content-based filtering.
- Seamlessly containerize your project using Docker for consistent deployment across different environments.
- Combine various recommendation strategies within one interactive application to deliver personalized recommendations.
This article was published as a part of the Data Science Blogathon.
Anime Recommendation System with Hugging Face: Data Collection
The foundation of any recommendation system lies in quality data. For this project, datasets were sourced from Kaggle and then stored in the Hugging Face Datasets Hub for streamlined access and integration. The primary datasets used include:
- Animes: A dataset detailing anime titles and associated metadata.
- Anime_UserRatings: User rating data for each anime.
- UserRatings: General user ratings providing insights into viewing habits.
Pre-requisites for Anime Recommendation App
Before we begin, ensure that you have completed the following steps:
1. Sign Up and Log In
- Go to Hugging Face and create an account if you haven’t already.
- Log in to your Hugging Face account to access the Spaces section.
2. Create a New Space
- Navigate to the “Spaces” section from your profile or dashboard.
- Click on the “Create New Space” button.
- Provide a unique name for your space and choose the “Streamlit” option for the app interface.
- Set your space to public or private based on your preference.
3. Clone the Space Repository
- After creating the Space, you’ll be redirected to the repository page for your new space.
- Clone the repository to your local machine using Git with the following command:
git clone https://huggingface.co/spaces/your-username/your-space-name4. Set Up the Virtual Environment
- Navigate to your project directory and create a new virtual environment using Python’s built-in venv tool.
# Creating the Virtual environment
## For macOS and Linux:
python3 -m venv env
## For Windows:
python -m venv env
# Activation the environment
## For macOS and Linux:
source env/bin/activate
## For Windows:
.\env\Scripts\activate5. Install Dependencies
- In the cloned repository, create a requirements.txt file that lists all the dependencies your app requires (e.g., Streamlit, pandas, etc.).
- Install the dependencies using the command:
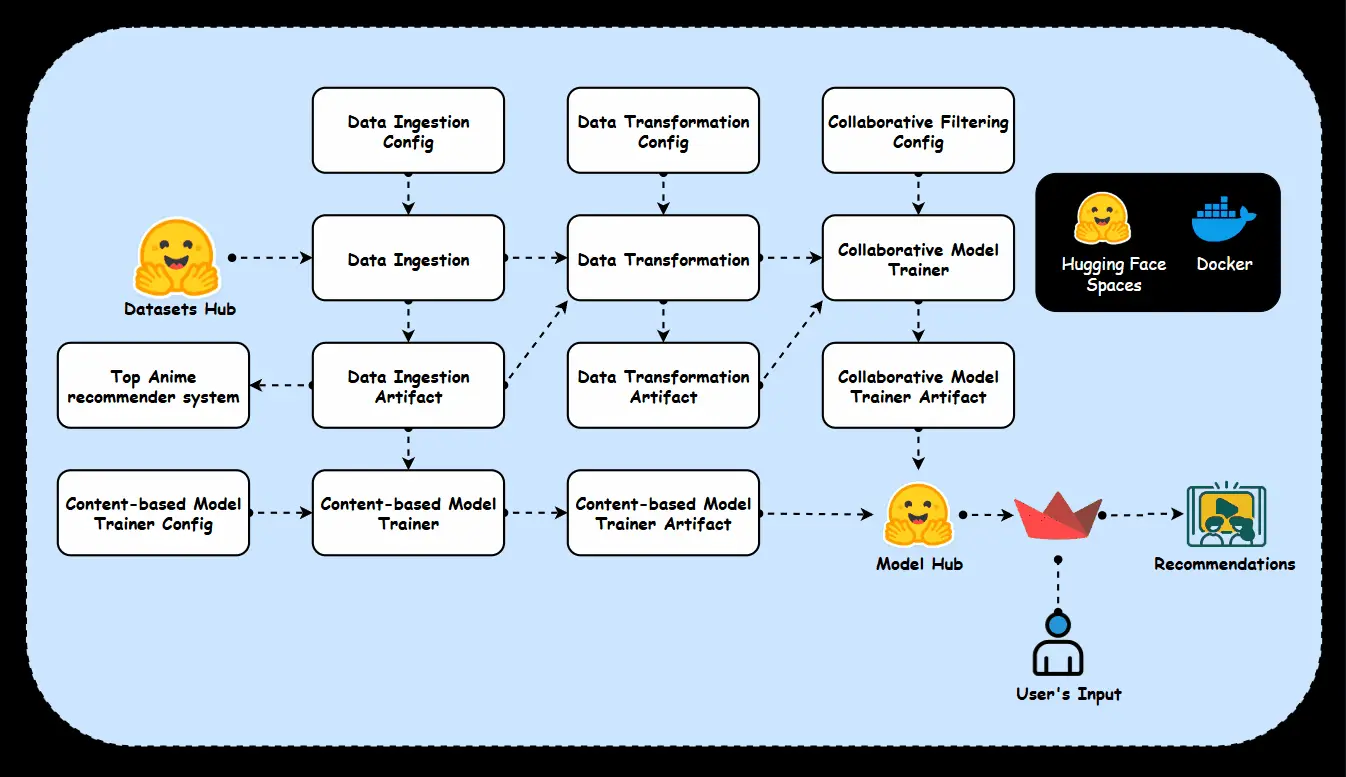
pip install -r requirements.txtBefore diving into the code, it is essential to understand how the various components of the system interact. Check out the below project architecture.
Folder Structure
This project adopts a modular folder structure designed to align with industry standards, ensuring scalability and maintainability.
ANIME-RECOMMENDATION-SYSTEM/ # Project directory
├── anime_recommender/ # Main package containing all the modules
│ │── __init__.py # Package initialization
│ │
│ ├── components/ # Core components of the recommendation system
│ │ │── __init__.py # Package initialization
│ │ │── collaborative_recommender.py # Collaborative filtering model
│ │ │── content_based_recommender.py # Content-based filtering model
│ │ │── data_ingestion.py # Fetches and loads data
│ │ │── data_transformation.py # Preprocesses and transforms the data
│ │ │── top_anime_recommenders.py # Filters top animes
│ │
│ ├── constant/
│ │ │── __init__.py # Stores constant values used across the project
│ │
│ ├── entity/ # Defines structured entities like configs and artifacts
│ │ │── __init__.py
│ │ │── artifact_entity.py # Data structures for model artifacts
│ │ │── config_entity.py # Configuration parameters and settings
│ │
│ ├── exception/ # Custom exception handling
│ │ │── __init__.py
│ │ │── exception.py # Handles errors and exceptions
│ │
│ ├── loggers/ # Logging and monitoring setup
│ │ │── __init__.py
│ │ │── logging.py # Configures log settings
│ │
│ ├── model_trainer/ # Model training scripts
│ │ │── __init__.py
│ │ │── collaborative_modelling.py # Train collaborative filtering model
│ │ │── content_based_modelling.py # Train content-based model
│ │ │── top_anime_filtering.py # Filters top animes based on ratings
│ │
│ ├── pipelines/ # End-to-end ML pipelines
│ │ │── __init__.py
│ │ │── training_pipeline.py # Training pipeline
│ │
│ ├── utils/ # Utility functions
│ │ │── __init__.py
│ │ ├── main_utils/
│ │ │ │── __init__.py
│ │ │ │── utils.py # Utility functions for specific processing
├── notebooks/ # Jupyter notebooks for EDA and experimentation
│ ├── EDA.ipynb # Exploratory Data Analysis
│ ├── final_ARS.ipynb # Final implementation notebook
├── .gitattributes # Git configuration for handling file formats
├── .gitignore # Specifies files to ignore in version control
├── app.py # Main Streamlit app
├── Dockerfile # Docker configuration for containerization
├── README.md # Project documentation
├── requirements.txt # Dependencies and libraries
├── run_pipeline.py # Runs the entire training pipeline
├── setup.py # Setup script for package installationConstants
The constant/__init__.py file defines all essential constants, such as file paths, directory names, and model filenames. These constants standardize configurations across the data ingestion, transformation, and model training stages. This ensures consistency, maintainability, and easy access to key project configurations.
"""Defining common constant variables for training pipeline"""
PIPELINE_NAME: str = "AnimeRecommender"
ARTIFACT_DIR: str = "Artifacts"
ANIME_FILE_NAME: str = "Animes.csv"
RATING_FILE_NAME:str = "UserRatings.csv"
MERGED_FILE_NAME:str = "Anime_UserRatings.csv"
ANIME_FILE_PATH:str = "krishnaveni76/Animes"
RATING_FILE_PATH:str = "krishnaveni76/UserRatings"
ANIMEUSERRATINGS_FILE_PATH:str = "krishnaveni76/Anime_UserRatings"
MODELS_FILEPATH = "krishnaveni76/anime-recommendation-models"
"""Data Ingestion related constant start with DATA_INGESTION VAR NAME"""
DATA_INGESTION_DIR_NAME: str = "data_ingestion"
DATA_INGESTION_FEATURE_STORE_DIR: str = "feature_store"
DATA_INGESTION_INGESTED_DIR: str = "ingested"
"""Data Transformation related constant start with DATA_VALIDATION VAR NAME"""
DATA_TRANSFORMATION_DIR:str = "data_transformation"
DATA_TRANSFORMATION_TRANSFORMED_DATA_DIR:str = "transformed"
"""Model Trainer related constant start with MODEL TRAINER VAR NAME"""
MODEL_TRAINER_DIR_NAME: str = "trained_models"
MODEL_TRAINER_COL_TRAINED_MODEL_DIR: str = "collaborative_recommenders"
MODEL_TRAINER_SVD_TRAINED_MODEL_NAME: str = "svd.pkl"
MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME: str = "itembasedknn.pkl"
MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME: str = "userbasedknn.pkl"
MODEL_TRAINER_CON_TRAINED_MODEL_DIR:str = "content_based_recommenders"
MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME:str = "cosine_similarity.pkl"Utils
The utils/main_utils/utils.py file contains utility functions for operations such as saving/loading data, exporting dataframes, saving models, and uploading models to Hugging Face. These reusable functions streamline processes throughout the project.
def export_data_to_dataframe(dataframe: pd.DataFrame, file_path: str) -> pd.DataFrame:
dir_path = os.path.dirname(file_path)
os.makedirs(dir_path, exist_ok=True)
dataframe.to_csv(file_path, index=False, header=True)
return dataframe
def load_csv_data(file_path: str) -> pd.DataFrame:
df = pd.read_csv(file_path)
return df
def save_model(model: object, file_path: str) -> None:
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, "wb") as file_obj:
joblib.dump(model, file_obj)
def load_object(file_path: str) -> object:
if not os.path.exists(file_path):
error_msg = f"The file: {file_path} does not exist."
raise Exception(error_msg)
with open(file_path, "rb") as file_obj:
return joblib.load(file_obj)
def upload_model_to_huggingface(model_path: str, repo_id: str, filename: str):
api = HfApi()
api.upload_file(path_or_fileobj=model_path,path_in_repo=filename,=repo_id,repo_type="model" ) Configuration Setup
The entity/config_entity.py file holds configuration details for different stages of the training pipeline. This includes paths for data ingestion, transformation, and model training for both collaborative and content-based recommendation systems. These configurations ensure a structured and organized workflow throughout the project.
class TrainingPipelineConfig:
def __init__(self, timestamp=datetime.now()):
timestamp = timestamp.strftime("%m_%d_%Y_%H_%M_%S")
self.pipeline_name = PIPELINE_NAME
self.artifact_dir = os.path.join(ARTIFACT_DIR, timestamp)
self.model_dir=os.path.join("final_model")
self.timestamp: str = timestamp
class DataIngestionConfig:
def __init__(self, training_pipeline_config: TrainingPipelineConfig):
self.data_ingestion_dir: str = os.path.join(training_pipeline_config.artifact_dir, DATA_INGESTION_DIR_NAME)
self.feature_store_anime_file_path: str = os.path.join(self.data_ingestion_dir, DATA_INGESTION_FEATURE_STORE_DIR, ANIME_FILE_NAME)
self.feature_store_userrating_file_path: str = os.path.join(self.data_ingestion_dir, DATA_INGESTION_FEATURE_STORE_DIR, RATING_FILE_NAME)
self.anime_filepath: str = ANIME_FILE_PATH
self.rating_filepath: str = RATING_FILE_PATH
class DataTransformationConfig:
def __init__(self,training_pipeline_config:TrainingPipelineConfig):
self.data_transformation_dir:str = os.path.join(training_pipeline_config.artifact_dir,DATA_TRANSFORMATION_DIR)
self.merged_file_path:str = os.path.join(self.data_transformation_dir,DATA_TRANSFORMATION_TRANSFORMED_DATA_DIR,MERGED_FILE_NAME)
class CollaborativeModelConfig:
def __init__(self,training_pipeline_config:TrainingPipelineConfig):
self.model_trainer_dir:str = os.path.join(training_pipeline_config.artifact_dir,MODEL_TRAINER_DIR_NAME)
self.svd_trained_model_file_path:str = os.path.join(self.model_trainer_dir,MODEL_TRAINER_COL_TRAINED_MODEL_DIR,MODEL_TRAINER_SVD_TRAINED_MODEL_NAME)
self.user_knn_trained_model_file_path:str = os.path.join(self.model_trainer_dir,MODEL_TRAINER_COL_TRAINED_MODEL_DIR,MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME)
self.item_knn_trained_model_file_path:str = os.path.join(self.model_trainer_dir,MODEL_TRAINER_COL_TRAINED_MODEL_DIR,MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME)
class ContentBasedModelConfig:
def __init__(self,training_pipeline_config:TrainingPipelineConfig):
self.model_trainer_dir:str = os.path.join(training_pipeline_config.artifact_dir,MODEL_TRAINER_DIR_NAME)
self.cosine_similarity_model_file_path:str = os.path.join(self.model_trainer_dir,MODEL_TRAINER_CON_TRAINED_MODEL_DIR,MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME)Artifacts entity
The entity/artifact_entity.py file defines classes for artifacts generated at various stages. These artifacts help track and manage intermediate outputs such as processed datasets and trained models.
@dataclass
class DataIngestionArtifact:
feature_store_anime_file_path:str
feature_store_userrating_file_path:str
@dataclass
class DataTransformationArtifact:
merged_file_path:str
@dataclass
class CollaborativeModelArtifact:
svd_file_path:str
item_based_knn_file_path:str
user_based_knn_file_path:str
@dataclass
class ContentBasedModelArtifact:
cosine_similarity_model_file_path:strRecommendation System – Model Training
In this project, we implement three types of recommendation systems to enhance the anime recommendation experience:
- Collaborative Recommendation System
- Content-Based Recommendation System
- Top Anime Recommendation System
Each approach plays a unique role in delivering personalized recommendations. By breaking down each component, we will gain a deeper understanding.
1. Collaborative Recommendation System
This Collaborative Recommendation System suggests items to users based on the preferences and behaviours of other users. It operates under the assumption that if two users have shown similar interests in the past, they are likely to have similar preferences in the future. This approach is widely used in platforms like Netflix, Amazon, and anime recommendation engines to provide personalized suggestions. In our case, we apply this recommendation technique to identify users with similar preferences and suggest anime based on their shared interests.
We will follow the below workflow to build our recommendation system. Each step is carefully structured to ensure seamless integration, starting with data collection, followed by transformation, and finally training a model to generate meaningful recommendations.
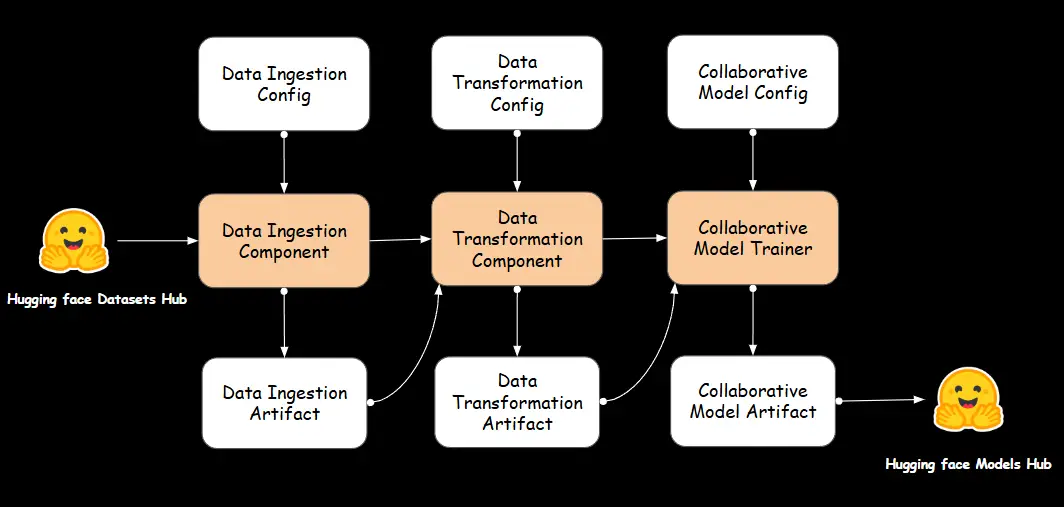
A. Data Ingestion
Data ingestion is the process of collecting, importing, and transferring data from various sources into a data storage system or pipeline for further processing and analysis. It is a crucial first step in any data-driven application, as it enables the system to access and work with the raw data required to generate insights, train models, or perform other tasks.
Data Ingestion Component
We define a DataIngestion class in components/data_ingestion.py file which handles the process of fetching datasets from Hugging Face Datasets Hub, and loading them into Pandas DataFrames. It utilizes DataIngestionConfig to obtain the necessary file paths and configurations for the ingestion process. The ingest_data method loads the anime and user rating datasets, exports them as CSV files to the feature store, and returns a DataIngestionArtifact containing the paths of the ingested files. This class encapsulates the data ingestion logic, ensuring that data is properly fetched, stored, and made accessible for further stages of the pipeline.
class DataIngestion:
def __init__(self, data_ingestion_config: DataIngestionConfig):
self.data_ingestion_config = data_ingestion_config
def fetch_data_from_huggingface(self, dataset_path: str, split: str = None) -> pd.DataFrame:
dataset = load_dataset(dataset_path, split=split)
df = pd.DataFrame(dataset['train'])
return df
def ingest_data(self) -> DataIngestionArtifact:
anime_df = self.fetch_data_from_huggingface(self.data_ingestion_config.anime_filepath)
rating_df = self.fetch_data_from_huggingface(self.data_ingestion_config.rating_filepath)
export_data_to_dataframe(anime_df, file_path=self.data_ingestion_config.feature_store_anime_file_path)
export_data_to_dataframe(rating_df, file_path=self.data_ingestion_config.feature_store_userrating_file_path)
dataingestionartifact = DataIngestionArtifact(
feature_store_anime_file_path=self.data_ingestion_config.feature_store_anime_file_path,
feature_store_userrating_file_path=self.data_ingestion_config.feature_store_userrating_file_path
)
return dataingestionartifact B. Data Transformation
Data transformation is the process of converting raw data into a format or structure that is suitable for analysis, modelling, or integration into a system. It is a crucial step in the data preprocessing pipeline, especially for machine learning, as it helps ensure that the data is clean, consistent, and formatted in a way that models can effectively use.
Data Transformation Component
In components/data_transformation.py file, we implement the DataTransformation class to manage the transformation of raw data into a cleaned and merged dataset, ready for further processing. The class includes methods to read data from CSV files, merge two datasets (anime and ratings), clean and filter the merged data. Specifically, the merge_data method combines the datasets based on a common column (anime_id), while the clean_filter_data method handles tasks like replacing missing values, converting columns to numeric types, filtering rows based on conditions, and removing unnecessary columns. The initiate_data_transformation method coordinates the entire transformation process, storing the resulting transformed dataset in the specified location using DataTransformationArtifact entity.
class DataTransformation:
def __init__(self,data_ingestion_artifact:DataIngestionArtifact,data_transformation_config:DataTransformationConfig):
self.data_ingestion_artifact = data_ingestion_artifact
self.data_transformation_config = data_transformation_config
@staticmethod
def read_data(file_path)->pd.DataFrame:
return pd.read_csv(file_path)
@staticmethod
def merge_data(anime_df: pd.DataFrame, rating_df: pd.DataFrame) -> pd.DataFrame:
merged_df = pd.merge(rating_df, anime_df, on="anime_id", how="inner")
return merged_df
@staticmethod
def clean_filter_data(merged_df: pd.DataFrame) -> pd.DataFrame:
merged_df['average_rating'].replace('UNKNOWN', np.nan)
merged_df['average_rating'] = pd.to_numeric(merged_df['average_rating'], errors="coerce")
merged_df['average_rating'].fillna(merged_df['average_rating'].median())
merged_df = merged_df[merged_df['average_rating'] > 6]
cols_to_drop = [ 'username', 'overview', 'type', 'episodes', 'producers', 'licensors', 'studios', 'source', 'rank', 'popularity', 'favorites', 'scored by', 'members' ]
cleaned_df = merged_df.copy()
cleaned_df.drop(columns=cols_to_drop, inplace=True)
return cleaned_df
def initiate_data_transformation(self)->DataTransformationArtifact:
anime_df = DataTransformation.read_data(self.data_ingestion_artifact.feature_store_anime_file_path)
rating_df = DataTransformation.read_data(self.data_ingestion_artifact.feature_store_userrating_file_path)
merged_df = DataTransformation.merge_data(anime_df, rating_df)
transformed_df = DataTransformation.clean_filter_data(merged_df)
export_data_to_dataframe(transformed_df, self.data_transformation_config.merged_file_path)
data_transformation_artifact = DataTransformationArtifact( merged_file_path=self.data_transformation_config.merged_file_path)
return data_transformation_artifact C. Collaborative Recommender
The Collaborative filtering is widely used in recommendation systems, where predictions are made based on user-item interactions rather than explicit features of the items.
Collaborative Modelling
The CollaborativeAnimeRecommender class is designed to provide personalized anime recommendations using collaborative filtering techniques. It employs three different models:
- Singular Value Decomposition (SVD) :– A matrix factorization technique that learns latent factors representing user preferences and anime characteristics, enabling personalized recommendations based on past ratings.
- Item-Based K-Nearest Neighbors (KNN) :– Finds similar anime titles based on user rating patterns, recommending shows similar to a given anime.
- User-Based K-Nearest Neighbors (KNN) :– Identifies users with similar preferences and suggests anime that like-minded users have enjoyed.
The class processes raw user ratings, constructs interaction matrices, and trains the models to generate tailored recommendations. The recommender provides predictions for individual users, recommends similar anime titles, and suggests new shows based on user similarity. By leveraging collaborative filtering techniques, this system enhances user experience by offering personalized and relevant anime recommendations.
class CollaborativeAnimeRecommender:
def __init__(self, df):
self.df = df
self.svd = None
self.knn_item_based = None
self.knn_user_based = None
self.prepare_data()
def prepare_data(self):
self.df = self.df.drop_duplicates()
reader = Reader(rating_scale=(1, 10))
self.data = Dataset.load_from_df(self.df[['user_id', 'anime_id', 'rating']], reader)
self.anime_pivot = self.df.pivot_table(index='name', columns="user_id", values="rating").fillna(0)
self.user_pivot = self.df.pivot_table(index='user_id', columns="name", values="rating").fillna(0)
def train_svd(self):
self.svd = SVD()
cross_validate(self.svd, self.data, cv=5)
trainset = self.data.build_full_trainset()
self.svd.fit(trainset)
def train_knn_item_based(self):
item_user_matrix = csr_matrix(self.anime_pivot.values)
self.knn_item_based = NearestNeighbors(metric="cosine", algorithm='brute')
self.knn_item_based.fit(item_user_matrix)
def train_knn_user_based(self):
user_item_matrix = csr_matrix(self.user_pivot.values)
self.knn_user_based = NearestNeighbors(metric="cosine", algorithm='brute')
self.knn_user_based.fit(user_item_matrix)
def print_unique_user_ids(self):
unique_user_ids = self.df['user_id'].unique()
return unique_user_ids
def get_svd_recommendations(self, user_id, n=10, svd_model=None)-> pd.DataFrame:
svd_model = svd_model or self.svd
if svd_model is None:
raise ValueError("SVD model is not provided or trained.")
if user_id not in self.df['user_id'].unique():
return f"User ID '{user_id}' not found in the dataset."
anime_ids = self.df['anime_id'].unique()
predictions = [(anime_id, svd_model.predict(user_id, anime_id).est) for anime_id in anime_ids]
predictions.sort(key=lambda x: x[1], reverse=True)
recommended_anime_ids = [pred[0] for pred in predictions[:n]]
recommended_anime = self.df[self.df['anime_id'].isin(recommended_anime_ids)].drop_duplicates(subset="anime_id")
recommended_anime = recommended_anime.head(n)
return pd.DataFrame({ 'Anime Name': recommended_anime['name'].values, 'Genres': recommended_anime['genres'].values, 'Image URL': recommended_anime['image url'].values, 'Rating': recommended_anime['average_rating'].values})
def get_item_based_recommendations(self, anime_name, n_recommendations=10, knn_item_model=None):
knn_item_based = knn_item_model or self.knn_item_based
if knn_item_based is None:
raise ValueError("Item-based KNN model is not provided or trained.")
if anime_name not in self.anime_pivot.index:
return f"Anime title '{anime_name}' not found in the dataset."
query_index = self.anime_pivot.index.get_loc(anime_name)
distances, indices = knn_item_based.kneighbors( self.anime_pivot.iloc[query_index, :].values.reshape(1, -1), n_neighbors=n_recommendations + 1 )
recommendations = []
for i in range(1, len(distances.flatten())):
anime_title = self.anime_pivot.index[indices.flatten()[i]]
distance = distances.flatten()[i]
recommendations.append((anime_title, distance))
recommended_anime_titles = [rec[0] for rec in recommendations]
filtered_df = self.df[self.df['name'].isin(recommended_anime_titles)].drop_duplicates(subset="name")
filtered_df = filtered_df.head(n_recommendations)
return pd.DataFrame({ 'Anime Name': filtered_df['name'].values, 'Image URL': filtered_df['image url'].values, 'Genres': filtered_df['genres'].values, 'Rating': filtered_df['average_rating'].values })
def get_user_based_recommendations(self, user_id, n_recommendations=10, knn_user_model=None)-> pd.DataFrame:
knn_user_based = knn_user_model or self.knn_user_based
if knn_user_based is None:
raise ValueError("User-based KNN model is not provided or trained.")
user_id = float(user_id)
if user_id not in self.user_pivot.index:
return f"User ID '{user_id}' not found in the dataset."
user_idx = self.user_pivot.index.get_loc(user_id)
distances, indices = knn_user_based.kneighbors( self.user_pivot.iloc[user_idx, :].values.reshape(1, -1), n_neighbors=n_recommendations + 1 )
user_rated_anime = set(self.user_pivot.columns[self.user_pivot.iloc[user_idx, :] > 0])
all_neighbor_ratings = []
for i in range(1, len(distances.flatten())):
neighbor_idx = indices.flatten()[i]
neighbor_rated_anime = self.user_pivot.iloc[neighbor_idx, :]
neighbor_ratings = neighbor_rated_anime[neighbor_rated_anime > 0]
all_neighbor_ratings.extend(neighbor_ratings.index)
anime_counter = Counter(all_neighbor_ratings)
recommendations = [(anime, count) for anime, count in anime_counter.items() if anime not in user_rated_anime]
recommendations.sort(key=lambda x: x[1], reverse=True)
recommended_anime_titles = [rec[0] for rec in recommendations[:n_recommendations]]
filtered_df = self.df[self.df['name'].isin(recommended_anime_titles)].drop_duplicates(subset="name")
filtered_df = filtered_df.head(n_recommendations)
return pd.DataFrame({ 'Anime Name': filtered_df['name'].values, 'Image URL': filtered_df['image url'].values, 'Genres': filtered_df['genres'].values, 'Rating': filtered_df['average_rating'].values }) Collaborative Model Trainer Component
The CollaborativeModelTrainer automates the training, saving, and deployment of the models. It ensures that trained models are stored locally and also uploaded to Hugging Face, making them easily accessible for generating recommendations.
class CollaborativeModelTrainer:
def __init__(self, collaborative_model_trainer_config: CollaborativeModelConfig, data_transformation_artifact: DataTransformationArtifact):
self.collaborative_model_trainer_config = collaborative_model_trainer_config
self.data_transformation_artifact = data_transformation_artifact
def initiate_model_trainer(self) -> CollaborativeModelArtifact:
df = load_csv_data(self.data_transformation_artifact.merged_file_path)
recommender = CollaborativeAnimeRecommender(df)
# Train and save SVD model
recommender.train_svd()
save_model(model=recommender.svd,file_path= self.collaborative_model_trainer_config.svd_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.svd_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_SVD_TRAINED_MODEL_NAME
)
svd_model = load_object(self.collaborative_model_trainer_config.svd_trained_model_file_path)
svd_recommendations = recommender.get_svd_recommendations(user_id=436, n=10, svd_model=svd_model)
# Train and save Item-Based KNN model
recommender.train_knn_item_based()
save_model(model=recommender.knn_item_based, file_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME
)
item_knn_model = load_object(self.collaborative_model_trainer_config.item_knn_trained_model_file_path)
item_based_recommendations = recommender.get_item_based_recommendations(
anime_name="One Piece", n_recommendations=10, knn_item_model=item_knn_model
)
# Train and save User-Based KNN model
recommender.train_knn_user_based()
save_model(model=recommender.knn_user_based,file_path= self.collaborative_model_trainer_config.user_knn_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.user_knn_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME
)
user_knn_model = load_object(self.collaborative_model_trainer_config.user_knn_trained_model_file_path)
user_based_recommendations = recommender.get_user_based_recommendations(
user_id=817, n_recommendations=10, knn_user_model=user_knn_model
)
return CollaborativeModelArtifact(
svd_file_path=self.collaborative_model_trainer_config.svd_trained_model_file_path,
item_based_knn_file_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path,
user_based_knn_file_path=self.collaborative_model_trainer_config.user_knn_trained_model_file_path
) 2. Content-Based Recommendation System
This content-based recommendation system suggests items to users by analyzing the attributes of items such as genre, keywords, or descriptions to generate recommendations based on similarity.
For example, in an anime recommendation system, if a user enjoys a particular anime, the model identifies similar anime based on attributes like genre, voice actors, or themes. Techniques such as TF-IDF (Term Frequency-Inverse Document Frequency), cosine similarity, and machine learning models help in ranking and suggesting relevant items.
Unlike collaborative filtering, which depends on user interactions, content-based filtering is independent of other users’ preferences, making it effective even in cases with fewer user interactions (cold start problem).
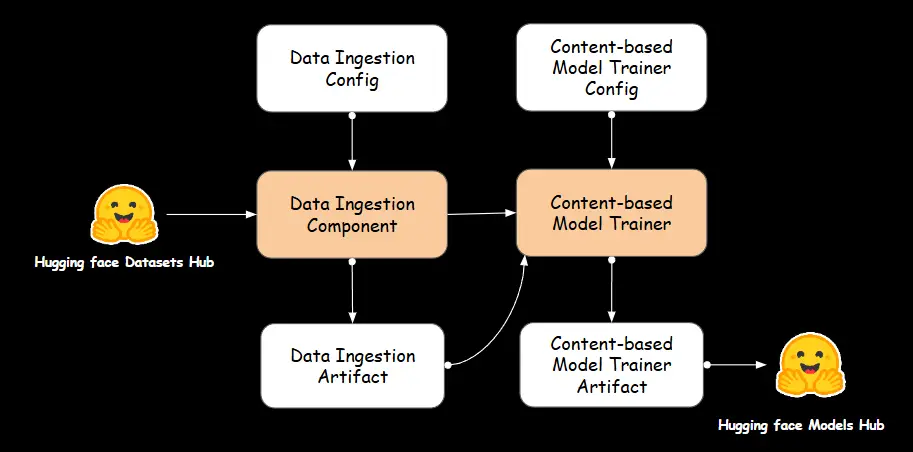
A. Data Ingestion
We use the artifacts from the data ingestion component discussed earlier to train the content-based recommender.
B. Content-Based Recommender
The Content-Based recommender is responsible for training recommendation models that analyze item attributes to generate personalized suggestions. It processes data, extracts relevant features, and builds models that identify similarities between items based on their content.
Content-Based Modelling
The ContentBasedRecommender class leverages TF-IDF (Term Frequency-Inverse Document Frequency) and Cosine Similarity to suggest anime based on their genre similarities. The model first processes the dataset by removing missing values and converting textual genre information into numerical feature vectors using TF-IDF vectorization. It then computes the cosine similarity between anime titles to measure their content similarity. The trained model is saved and later used to provide personalized recommendations by retrieving the most similar anime based on a given title.
class ContentBasedRecommender:
def __init__(self, df):
self.df = df.dropna()
self.indices = pd.Series(self.df.index, index=self.df['name']).drop_duplicates()
self.tfv = TfidfVectorizer( min_df=3, strip_accents="unicode", analyzer="word", token_pattern=r'\w{1,}', ngram_range=(1, 3), stop_words="english" )
self.tfv_matrix = self.tfv.fit_transform(self.df['genres'])
self.cosine_sim = cosine_similarity(self.tfv_matrix, self.tfv_matrix)
def save_model(self, model_path):
os.makedirs(os.path.dirname(model_path), exist_ok=True)
with open(model_path, 'wb') as f:
joblib.dump((self.tfv, self.cosine_sim), f)
def get_rec_cosine(self, title, model_path, n_recommendations=5):
with open(model_path, 'rb') as f:
self.tfv, self.cosine_sim = joblib.load(f)
if self.df is None:
raise ValueError("The DataFrame is not loaded, cannot make recommendations.")
if title not in self.indices.index:
return f"Anime title '{title}' not found in the dataset."
idx = self.indicesHow to Build an Anime Recommendation System?
cosinesim_scores = list(enumerate(self.cosine_sim[idx]))
cosinesim_scores = sorted(cosinesim_scores, key=lambda x: x[1], reverse=True)[1:n_recommendations + 1]
anime_indices = [i[0] for i in cosinesim_scores]
return pd.DataFrame({ 'Anime name': self.df['name'].iloc[anime_indices].values, 'Image URL': self.df['image url'].iloc[anime_indices].values, 'Genres': self.df['genres'].iloc[anime_indices].values, 'Rating': self.df['average_rating'].iloc[anime_indices].values }) Content-Based Model Trainer Component
The ContentBasedModelTrainer class is responsible for automating the training and deployment of a content-based recommendation model. It loads the processed anime dataset from the data ingestion artifact, initializes the ContentBasedRecommender, and trains it using TF-IDF vectorization and cosine similarity. The trained model is then saved and uploaded to Hugging Face.
class ContentBasedModelTrainer:
def __init__(self, content_based_model_trainer_config: ContentBasedModelConfig, data_ingestion_artifact: DataIngestionArtifact):
self.content_based_model_trainer_config = content_based_model_trainer_config
self.data_ingestion_artifact = data_ingestion_artifact
def initiate_model_trainer(self) -> ContentBasedModelArtifact:
df = load_csv_data(self.data_ingestion_artifact.feature_store_anime_file_path)
recommender = ContentBasedRecommender(df=df )
recommender.save_model(model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path)
upload_model_to_huggingface(
model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME
)
cosine_recommendations = recommender.get_rec_cosine(title="One Piece", model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path, n_recommendations=10)
content_model_trainer_artifact = ContentBasedModelArtifact( cosine_similarity_model_file_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path )
return content_model_trainer_artifact3. Top Anime Recommendation System
It is common for newcomers to anime to seek out the most popular titles first. This top anime recommendation system is designed to help those new to the anime world easily discover popular, highly rated, and top-ranked anime all in one place by using simple sorting and filtering.
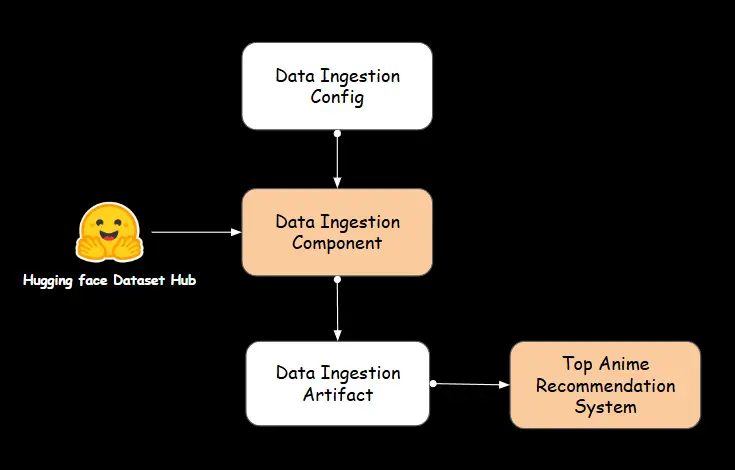
A. Data Ingestion
We utilize the artifacts from the previously discussed data ingestion component in this recommendation system.
B. Top Anime Recommender Component
Top anime filtering
The PopularityBasedFiltering class is responsible for ranking and sorting anime using predefined popularity-based parameters. It analyzes the dataset by evaluating attributes such as rating, number of favorites, community size, and ranking position. The class includes specialized functions to extract top-performing anime within each category, ensuring a structured approach to filtering. Additionally, it manages missing data and refines the output for readability. By providing data-driven insights, this class plays a crucial role in identifying popular and highly-rated anime for recommendation purposes.
class PopularityBasedFiltering:
def __init__(self, df):
self.df = df
self.df['average_rating'] = pd.to_numeric(self.df['average_rating'], errors="coerce")
self.df['average_rating'].fillna(self.df['average_rating'].median())
def popular_animes(self, n=10):
sorted_df = self.df.sort_values(by=['popularity'], ascending=True)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def top_ranked_animes(self, n=10):
self.df['rank'] = self.df['rank'].replace('UNKNOWN', np.nan).astype(float)
df_filtered = self.df[self.df['rank'] > 1]
sorted_df = df_filtered.sort_values(by=['rank'], ascending=True)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def overall_top_rated_animes(self, n=10):
sorted_df = self.df.sort_values(by=['average_rating'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def favorite_animes(self, n=10):
sorted_df = self.df.sort_values(by=['favorites'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def top_animes_members(self, n=10):
sorted_df = self.df.sort_values(by=['members'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def popular_anime_among_members(self, n=10):
sorted_df = self.df.sort_values(by=['members', 'average_rating'], ascending=[False, False]).drop_duplicates(subset="name")
popular_animes = sorted_df.head(n)
return self._format_output(popular_animes)
def top_avg_rated(self, n=10):
self.df['average_rating'] = pd.to_numeric(self.df['average_rating'], errors="coerce")
median_rating = self.df['average_rating'].median()
self.df['average_rating'].fillna(median_rating)
top_animes = ( self.df.drop_duplicates(subset="name").nlargest(n, 'average_rating')[['name', 'average_rating', 'image url', 'genres']] )
return self._format_output(top_animes)
def _format_output(self, anime_df):
return pd.DataFrame({ 'Anime name': anime_df['name'].values, 'Image URL': anime_df['image url'].values, 'Genres': anime_df['genres'].values, 'Rating': anime_df['average_rating'].values })Top anime recommenders
The PopularityBasedRecommendor class is responsible for recommending anime based on different popularity metrics. It utilizes an anime dataset stored in feature_store_anime_file_path, which was a DataIngestionArtifact. The class integrates the PopularityBasedFiltering class to generate anime recommendations according to various filtering criteria, such as top-ranked anime, most popular choices, community favorites, and highest-rated shows. By selecting a specific filter_type, users can retrieve the best match based on their preferred criteria.
class PopularityBasedRecommendor:
def __init__(self,data_ingestion_artifact = DataIngestionArtifact):
self.data_ingestion_artifact = data_ingestion_artifact
def initiate_model_trainer(self,filter_type:str):
df = load_csv_data(self.data_ingestion_artifact.feature_store_anime_file_path)
recommender = PopularityBasedFiltering(df)
if filter_type == 'popular_animes':
popular_animes = recommender.popular_animes(n =10)
elif filter_type == 'top_ranked_animes':
top_ranked_animes = recommender.top_ranked_animes(n =10)
elif filter_type == 'overall_top_rated_animes':
overall_top_rated_animes = recommender.overall_top_rated_animes(n =10)
elif filter_type == 'favorite_animes':
favorite_animes = recommender.favorite_animes(n =10)
elif filter_type == 'top_animes_members':
top_animes_members = recommender.top_animes_members(n = 10)
elif filter_type == 'popular_anime_among_members':
popular_anime_among_members = recommender.popular_anime_among_members(n =10)
elif filter_type == 'top_avg_rated':
top_avg_rated = recommender.top_avg_rated(n =10) Training Pipeline
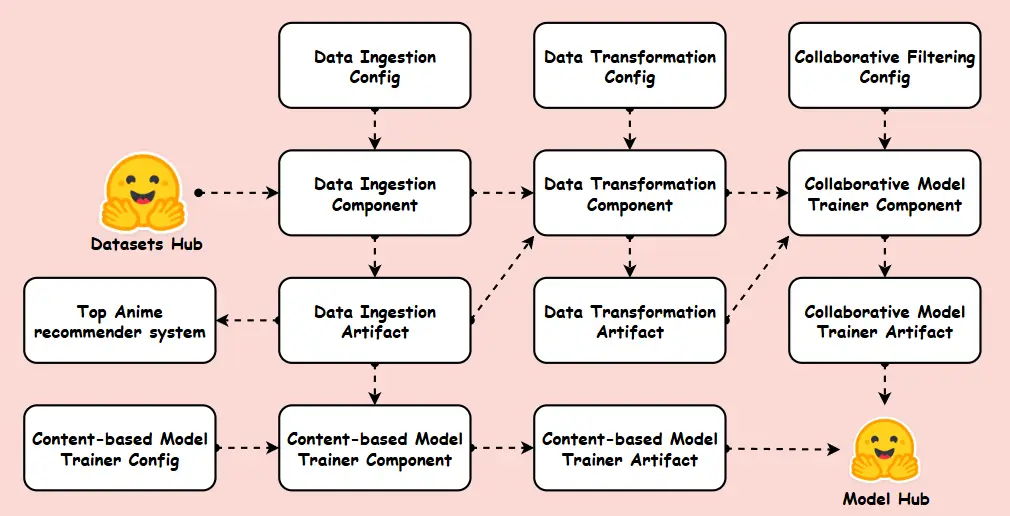
This Machine Learning Training Pipeline is designed to automate and streamline the process of building recommender models efficiently. The pipeline follows a structured workflow, beginning with data ingestion from Hugging face, followed by data transformation to preprocess and prepare the data for model training. It incorporates different modelling techniques, such as collaborative filtering, content-based approaches and Popularity-based filtering, ensuring optimal performance. The final trained models are stored in a Model Hub, enabling seamless deployment and continuous refinement. This structured approach ensures scalability, efficiency, and reproducibility in machine learning workflows.
class TrainingPipeline:
def __init__(self):
self.training_pipeline_config = TrainingPipelineConfig()
def start_data_ingestion(self) -> DataIngestionArtifact:
data_ingestion_config = DataIngestionConfig(self.training_pipeline_config)
data_ingestion = DataIngestion(data_ingestion_config=data_ingestion_config)
data_ingestion_artifact = data_ingestion.ingest_data()
return data_ingestion_artifact
def start_data_transformation(self, data_ingestion_artifact: DataIngestionArtifact) -> DataTransformationArtifact:
data_transformation_config = DataTransformationConfig(self.training_pipeline_config)
data_transformation = DataTransformation(
data_ingestion_artifact=data_ingestion_artifact,
data_transformation_config=data_transformation_config
)
data_transformation_artifact = data_transformation.initiate_data_transformation()
return data_transformation_artifact
def start_collaborative_model_training(self, data_transformation_artifact: DataTransformationArtifact) -> CollaborativeModelArtifact:
collaborative_model_config = CollaborativeModelConfig(self.training_pipeline_config)
collaborative_model_trainer = CollaborativeModelTrainer(
collaborative_model_trainer_config=collaborative_model_config,
data_transformation_artifact=data_transformation_artifact )
collaborative_model_trainer_artifact = collaborative_model_trainer.initiate_model_trainer()
return collaborative_model_trainer_artifact
def start_content_based_model_training(self, data_ingestion_artifact: DataIngestionArtifact) -> ContentBasedModelArtifact:
content_based_model_config = ContentBasedModelConfig(self.training_pipeline_config)
content_based_model_trainer = ContentBasedModelTrainer(
content_based_model_trainer_config=content_based_model_config,
data_ingestion_artifact=data_ingestion_artifact )
content_based_model_trainer_artifact = content_based_model_trainer.initiate_model_trainer()
return content_based_model_trainer_artifact
def start_popularity_based_filtering(self, data_ingestion_artifact: DataIngestionArtifact):
filtering = PopularityBasedRecommendor(data_ingestion_artifact=data_ingestion_artifact)
recommendations = filtering.initiate_model_trainer(filter_type="popular_animes")
return recommendations
def run_pipeline(self):
# Data Ingestion
data_ingestion_artifact = self.start_data_ingestion()
# Content-Based Model Training
content_based_model_trainer_artifact = self.start_content_based_model_training(data_ingestion_artifact)
# Popularity-Based Filtering
popularity_recommendations = self.start_popularity_based_filtering(data_ingestion_artifact)
# Data Transformation
data_transformation_artifact = self.start_data_transformation(data_ingestion_artifact)
# Collaborative Model Training
collaborative_model_trainer_artifact = self.start_collaborative_model_training(data_transformation_artifact)Now that we’ve completed creating the pipeline, run the training_pipeline.py file using the below code to view the artifacts generated in the previous steps.
python training_pipeline.py Streamlit App
The recommendation application is built using Streamlit, a lightweight and interactive framework for creating data-driven web apps. It is deployed on Hugging Face Spaces, allowing users to explore and interact with the anime recommendation system seamlessly. This setup provides an intuitive UI for discovering anime recommendations in real time. Each time you push new changes, Hugging Face will redeploy your app automatically.
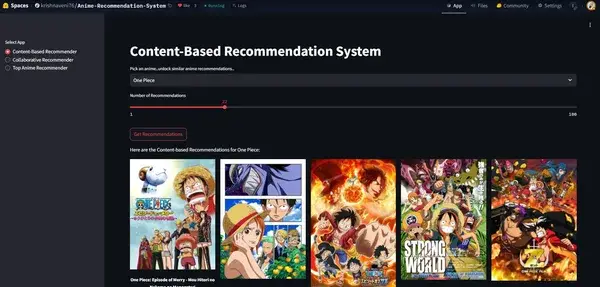
Docker Integration for Deployment
The Dockerfile sets up a lightweight Python environment using the official Python 3.10 slim-buster image. It configures the working directory, copies application files, and installs dependencies from requirements.txt. Finally, it exposes port 8501 and runs the Streamlit app, making it accessible within the containerized environment.
# Use the official Python image as a base
FROM python:3.10-slim-buster
# Set the working directory in the container
WORKDIR /app
# Copy the app files into the container
COPY . .
# Install required packages
RUN pip install -r requirements.txt
# Expose the port that Streamlit uses
EXPOSE 8501
# Run the Streamlit app
CMD ["streamlit", "run", "app.py", "--server.port=8501", "--server.address=0.0.0.0"] Key Takeaways
- We have designed an efficient, end-to-end pipeline that ensures smooth data flow from ingestion to recommendation, making the system scalable, robust, and production-ready.
- New users receive trending anime suggestions via a popularity-based engine, while returning users get hyper-personalized picks through collaborative filtering models.
- By deploying on Hugging Face Spaces with model versioning, you achieve cost-free productionization without paying any AWS/GCP bills while maintaining scalability!
- The system leverages Docker for containerization, ensuring consistent environments across different deployments.
- Built using Streamlit, the app provides a clean, dynamic, and engaging user experience, making anime discovery fun and intuitive.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Conclusion
Congratulations! You have completed building the Recommendation app in no time. From acquiring data and preprocessing it to model training and deployment, this project highlights the power of getting things out there into the world! But hold up… we’re not done yet! 💥 There’s a whole lot more fun to come! You’re now ready to build on something even cooler, like a Movie Recommendation app!
This is just the beginning of our adventure together, so buckle up—there are many more exciting projects ahead! Let’s keep learning and building!
Frequently Asked Questions
Ans. Absolutely! Swap the dataset, adjust genre weights in constants.py, and voilà – you’ve got a Squid Game or Marvel Recommender in no time!
Ans. Yes! A “Surprise Me” button can be easily added using random.choice(), helping users discover hidden anime gems randomly!
Ans. Their free tier handles ~10K monthly visits. If you hit Demon Slayer levels of popularity, upgrade to PRO ($9/month) for priority servers.
Hello! I’m a passionate AI and Machine Learning enthusiast currently exploring the exciting realms of Deep Learning, MLOps, and Generative AI. I enjoy diving into new projects and uncovering innovative techniques that push the boundaries of technology. I’ll be sharing guides, tutorials, and project insights based on my own experiences, so we can learn and grow together. Join me on this journey as we explore, experiment, and build amazing solutions in the world of AI and beyond!