

In artificial intelligence, evaluating the performance of language models presents a unique challenge. Unlike image recognition or numerical predictions, language quality assessment doesn’t yield to simple binary measurements. Enter BLEU (Bilingual Evaluation Understudy), a metric that has become the cornerstone of machine translation evaluation since its introduction by IBM researchers in 2002.
BLEU stands for a breakthrough in natural language processing for it is the very first evaluation method that manages to achieve a pretty high correlation with human judgment and yet retains the efficiency of automation. This article investigates the mechanics of BLEU, its applications, its limitations, and what the future holds for it in an increasingly AI-driven world that is preoccupied with richer nuances in language-generated output.
Note: This is a series of Evaluation Metrics of LLMs and I will be covering all the Top 15 LLM Evaluation Metrics to Explore in 2025.
The Genesis of BLEU Metric: A Historical Perspective
Prior to BLEU, evaluating machine translations was primarily manual—a resource-intensive process requiring lingual experts to manually assess each output. The introduction of BLEU by Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu at IBM Research represented a paradigm shift. Their 2002 paper, “BLEU: a Method for Automatic Evaluation of Machine Translation,” proposed an automated metric that could score translations with remarkable alignment to human judgment.
The timing was pivotal. As statistical machine translation systems were gaining momentum, the field urgently needed standardized evaluation methods. BLEU filled this void, offering a reproducible, language-independent scoring mechanism that facilitated meaningful comparisons between different translation systems.
How Does BLEU Metric Work?
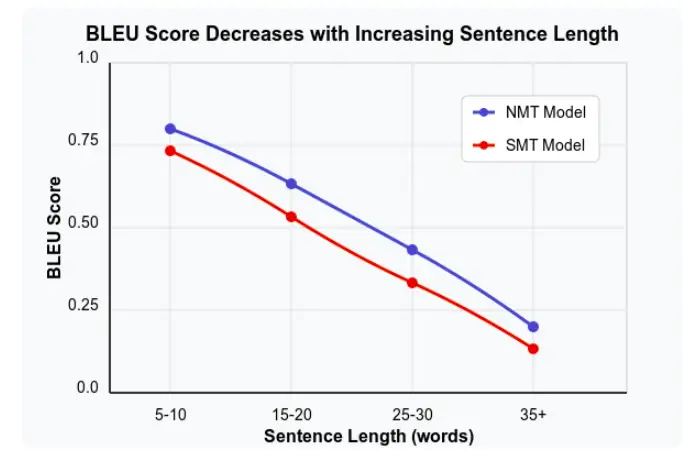
At its core, BLEU operates on a simple principle: comparing machine-generated translations against reference translations (typically created by human translators). It has been observed that the BLEU score decreases as the sentence length increases, though it might vary depending on the model used for translations. However, its implementation involves sophisticated computational linguistics concepts:
N-gram Precision
BLEU’s foundation lies in n-gram precision—the percentage of word sequences in the machine translation that appear in any reference translation. Rather than limiting itself to individual words (unigrams), BLEU examines contiguous sequences of various lengths:
- Unigrams (single words) Modified Precision: Measuring vocabulary accuracy
- Bigrams (two-word sequences) Modified Precision: Capturing basic phrasal correctness
- Trigrams and 4-grams Modified Precision: Evaluating grammatical structure and word order
BLEU calculates modified precision for each n-gram length by:
- Counting n-gram matches between the candidate and reference translations
- Applying a “clipping” mechanism to prevent overinflation from repeated words
- Dividing by the total number of n-grams in the candidate translation
Brevity Penalty
To prevent systems from gaming the metric by producing extremely short translations (which could achieve high precision by including only easily matched words), BLEU incorporates a brevity penalty that reduces scores for translations shorter than their references.
The penalty is calculated as:
BP = exp(1 - r/c) if c Where r is the reference length and c is the candidate translation length.
The Final BLEU Score
The final BLEU score combines these components into a single value between 0 and 1 (often presented as a percentage):
BLEU = BP × exp(∑ wn log pn)Where:
- BP is the brevity penalty
- wn represents weights for each n-gram precision (typically uniform)
- pn is the modified precision for n-grams of length n
Implementing BLEU Metric
Understanding BLEU conceptually is one thing; implementing it correctly requires attention to detail. Here’s a practical guide to using BLEU effectively:
Required Inputs
BLEU requires two primary inputs:
- Candidate translations: The machine-generated translations you want to evaluate
- Reference translations: One or more human-created translations for each source sentence
Both inputs must undergo consistent preprocessing:
- Tokenization: Breaking text into words or subwords
- Case normalization: Typically lowercasing all text
- Punctuation handling: Either removing punctuation or treating punctuation marks as separate tokens
Implementation Steps
A typical BLEU implementation follows these steps:
- Preprocess all translations: Apply consistent tokenization and normalization
- Calculate n-gram precision for n=1 to N (typically N=4):
- Count all n-grams in the candidate translation
- Count matching n-grams in reference translations (with clipping)
- Compute precision as (matches / total candidate n-grams)
- Calculate brevity penalty:
- Determine effective reference length (shortest ref length in original BLEU)
- Compared to the candidate length
- Apply brevity penalty formula
- Combine components into the final score:
- Apply weighted geometric mean of n-gram precisions
- Multiply by brevity penalty
Several libraries provide ready-to-use BLEU implementations:
NLTK: Python’s Natural Language Toolkit offers a simple BLEU implementation
from nltk.translate.bleu_score import sentence_bleu, corpus_bleu
from nltk.translate.bleu_score import SmoothingFunction
# Create a smoothing function to avoid zero scores due to missing n-grams
smoothie = SmoothingFunction().method1
# Example 1: Single reference, good match
reference = [['this', 'is', 'a', 'test']]
candidate = ['this', 'is', 'a', 'test']
score = sentence_bleu(reference, candidate)
print(f"Perfect match BLEU score: {score}")
# Example 2: Single reference, partial match
reference = [['this', 'is', 'a', 'test']]
candidate = ['this', 'is', 'test']
# Using smoothing to avoid zero scores
score = sentence_bleu(reference, candidate, smoothing_function=smoothie)
print(f"Partial match BLEU score: {score}")
# Example 3: Multiple references (corrected format)
references = [[['this', 'is', 'a', 'test']], [['this', 'is', 'an', 'evaluation']]]
candidates = [['this', 'is', 'an', 'assessment']]
# The format for corpus_bleu is different - references need restructuring
correct_references = [[['this', 'is', 'a', 'test'], ['this', 'is', 'an', 'evaluation']]]
score = corpus_bleu(correct_references, candidates, smoothing_function=smoothie)
print(f"Multiple reference BLEU score: {score}")Output
Perfect match BLEU score: 1.0
Partial match BLEU score: 0.19053627645285995
Multiple reference BLEU score: 0.3976353643835253
SacreBLEU: A standardized BLEU implementation that addresses reproducibility concerns
import sacrebleu
# For sentence-level BLEU with SacreBLEU
reference = ["this is a test"] # List containing a single reference
candidate = "this is a test" # String containing the hypothesis
score = sacrebleu.sentence_bleu(candidate, reference)
print(f"Perfect match SacreBLEU score: {score}")
# Partial match example
reference = ["this is a test"]
candidate = "this is test"
score = sacrebleu.sentence_bleu(candidate, reference)
print(f"Partial match SacreBLEU score: {score}")
# Multiple references example
references = ["this is a test", "this is a quiz"] # List of multiple references
candidate = "this is an exam"
score = sacrebleu.sentence_bleu(candidate, references)
print(f"Multiple references SacreBLEU score: {score}")Output
Perfect match SacreBLEU score: BLEU = 100.00 100.0/100.0/100.0/100.0 (BP =
1.000 ratio = 1.000 hyp_len = 4 ref_len = 4)Partial match SacreBLEU score: BLEU = 45.14 100.0/50.0/50.0/0.0 (BP = 0.717
ratio = 0.750 hyp_len = 3 ref_len = 4)Multiple references SacreBLEU score: BLEU = 31.95 50.0/33.3/25.0/25.0 (BP =
1.000 ratio = 1.000 hyp_len = 4 ref_len = 4)
Hugging Face Evaluate: Modern implementation integrated with ML pipelines
from evaluate import load
bleu = load('bleu')
# Example 1: Perfect match
predictions = ["this is a test"]
references = [["this is a test"]]
results = bleu.compute(predictions=predictions, references=references)
print(f"Perfect match HF Evaluate BLEU score: {results}")
# Example 2: Multi-sentence evaluation
predictions = ["the cat is on the mat", "there is a dog in the park"]
references = [["the cat sits on the mat"], ["a dog is running in the park"]]
results = bleu.compute(predictions=predictions, references=references)
print(f"Multi-sentence HF Evaluate BLEU score: {results}")
# Example 3: More complex real-world translations
predictions = ["The agreement on the European Economic Area was signed in August 1992."]
references = [["The agreement on the European Economic Area was signed in August 1992.", "An agreement on the European Economic Area was signed in August of 1992."]]
results = bleu.compute(predictions=predictions, references=references)
print(f"Complex example HF Evaluate BLEU score: {results}")Output
Perfect match HF Evaluate BLEU score: {'bleu': 1.0, 'precisions': [1.0, 1.0,
1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0,
'translation_length': 4, 'reference_length': 4}Multi-sentence HF Evaluate BLEU score: {'bleu': 0.0, 'precisions':
[0.8461538461538461, 0.5454545454545454, 0.2222222222222222, 0.0],
'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 13,
'reference_length': 13}
Complex example HF Evaluate BLEU score: {'bleu': 1.0, 'precisions': [1.0,
1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0,
'translation_length': 13, 'reference_length': 13}
Interpreting BLEU Outputs
BLEU scores typically range from 0 to 1 (or 0 to 100 when presented as percentages):
- 0: No matches between candidate and references
- 1 (or 100%): Perfect match with references
- Typical ranges:
- 0-15: Poor translation
- 15-30: Understandable but flawed translation
- 30-40: Good translation
- 40-50: High-quality translation
- 50+: Exceptional translation (potentially approaching human quality)
However, these ranges vary significantly between language pairs. For instance, translations between English and Chinese typically score lower than English-French pairs, due to linguistic differences rather than actual quality differences.
Score Variants
Different BLEU implementations may produce varying scores due to:
- Smoothing methods: Addressing zero precision values
- Tokenization differences: Especially important for languages without clear word boundaries
- N-gram weighting schemes: Standard BLEU uses uniform weights, but alternatives exist
For more information watch this video:
Beyond Translation: BLEU’s Expanding Applications
While BLEU was designed for machine translation evaluation, its influence has extended throughout natural language processing:
- Text Summarization – Researchers have adapted BLEU to evaluate automatic summarization systems, comparing model-generated summaries against human-created references. Though summarization poses unique challenges—such as the need for semantic preservation rather than exact wording—modified BLEU variants have proven valuable in this domain.
- Dialogue Systems and Chatbots – Conversational AI developers use BLEU to measure response quality in dialogue systems, though with important caveats. The open-ended nature of conversation means multiple responses can be equally valid, making reference-based evaluation particularly challenging. Nevertheless, BLEU provides a starting point for assessing response appropriateness.
- Image Captioning – In multimodal AI, BLEU helps evaluate systems that generate textual descriptions of images. By comparing model-generated captions against human annotations, researchers can quantify caption accuracy while acknowledging the creative aspects of description.
- Code Generation – An emerging application involves evaluating code generation models, where BLEU can measure the similarity between AI-generated code and reference implementations. This application highlights BLEU’s versatility across different types of structured language.
The Limitations: Why BLEU Isn’t Perfect?
Despite its widespread adoption, BLEU has well-documented limitations that researchers must consider:
- Semantic Blindness – Perhaps BLEU’s most significant limitation is its inability to capture semantic equivalence. Two translations can convey identical meanings using entirely different words, yet BLEU would assign a low score to the variant that doesn’t match the reference lexically. This “surface-level” evaluation can penalize valid stylistic choices and alternative phrasings.
- Lack of Contextual Understanding – BLEU treats sentences as isolated units, disregarding document-level coherence and contextual appropriateness. This limitation becomes particularly problematic when evaluating translations of texts where context significantly influences word choice and meaning.
- Insensitivity to Critical Errors – Not all translation errors carry equal weight. A minor word-order discrepancy might barely affect comprehensibility, while a single mistranslated negation could reverse a sentence’s entire meaning. BLEU treats these errors equally, failing to distinguish between trivial and critical mistakes.
- Reference Dependency – BLEU’s reliance on reference translations introduces inherent bias. The metric cannot recognize the merit of a valid translation that significantly differs from the provided references. This dependency also creates practical challenges in low-resource languages where obtaining multiple high-quality references is difficult.
Beyond BLEU: The Evolution of Evaluation Metrics
BLEU’s limitations have spurred the development of complementary metrics, each addressing specific shortcomings:
- METEOR (Metric for Evaluation of Translation with Explicit ORdering) – METEOR enhances evaluation by incorporating:
- Stemming and synonym matching to recognize semantic equivalence
- Explicit word-order evaluation
- Parameterized weighting of precision and recall
- chrF (Character n-gram F-score) – This metric operates at the character level rather than word level, making it particularly effective for morphologically rich languages where slight word variations can proliferate.
- BERTScore – Leveraging contextual embeddings from transformer models like BERT, this metric captures semantic similarity between translations and references, addressing BLEU’s semantic blindness.
- COMET (Crosslingual Optimized Metric for Evaluation of Translation) – COMET uses neural networks trained on human judgments to predict translation quality, potentially capturing aspects of translation that correlate with human perception but elude traditional metrics.
The Future of BLEU in an Era of Neural Machine Translation
As neural machine translation systems increasingly produce human-quality outputs, BLEU faces new challenges and opportunities:
- Ceiling Effects – Top-performing NMT systems now achieve BLEU scores approaching or exceeding human translators on certain language pairs. This “ceiling effect” raises questions about BLEU’s continued utility in distinguishing between high-performing systems.
- Human Parity Debates – Recent claims of “human parity” in machine translation have sparked debates about evaluation methodology. BLEU has become central to these discussions, with researchers questioning whether current metrics adequately capture translation quality at near-human levels.
- Customization for Domains – Different domains prioritize different aspects of translation quality. Medical translations demand terminology precision, while marketing content may value creative adaptation. Future BLEU implementations may incorporate domain-specific weightings to reflect these varying priorities.
- Integration with Human Feedback – The most promising direction may be hybrid evaluation approaches that combine automated metrics like BLEU with targeted human assessments. These methods could leverage BLEU’s efficiency while compensating for its blind spots through strategic human intervention.
Conclusion
Despite its limitations, BLEU remains fundamental to machine translation research and development. Its simplicity, reproducibility, and correlation with human judgment have established it as the lingua franca of translation evaluation. While newer metrics address specific BLEU weaknesses, none has fully displaced it.
The story of BLEU reflects a broader pattern in artificial intelligence: the tension between computational efficiency and nuanced evaluation. As language technologies advance, our methods for assessing them must evolve in parallel. BLEU’s greatest contribution may ultimately serve as the foundation upon which more sophisticated evaluation paradigms are built.
With the robotic mediation of communication between humans, metrics such as BLEU have grown to be not just an act of research but a safeguard ensuring that AI-powered language tools satisfy human needs. Understanding BLEU Metric in all its glory and limitations is indispensable for anyone working where technology meets language.
Gen AI Intern at Analytics Vidhya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as a Gen AI Intern at Analytics Vidhya, where I contribute to innovative AI-driven solutions that empower businesses to leverage data effectively. As a final-year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics, and machine learning to my role.
Feel free to connect with me at [email protected]
Login to continue reading and enjoy expert-curated content.






