Large language models answer questions using the knowledge they learned during training. This fixed knowledge base limits them. They can’t give you current or highly specific information. Retrieval-Augmented Generation (RAG) helps by letting LLMs pull in external data, but even RAG needs help with complex questions. Adaptive RAG offers a solution. It picks the best approach for answering a question. This could be a direct answer from the LLM, a single data lookup, or multiple data lookups or even a web search. A classifier looks at the question’s complexity and decides the best method.
Here are the three answering strategies Adaptive RAG uses:
- Straight forward Response: For easy questions, the LLM uses its own stored knowledge. This gives fast answers without needing to look up external information.
- Single-step Approach: For questions that are a bit harder, the system gets information from one external source. This keeps the answer quick but also well-informed.
- Multi-step Approach: For the most complex questions, the system looks at several sources. This builds a detailed and complete answer.
Why Adaptive-RAG Works So Well?
Adaptive-RAG is flexible. It handles each question efficiently, using only the resources needed. This saves computing power and makes users happier because they get precise answers quickly. Adaptive-RAG also updates itself based on question complexity. Because it adapts, it reduces the chance of old or too-general answers. It gives current, specific and reliable answers.
Improving Accuracy
Adaptive-RAG is very accurate. It understands the complexity of each question and adapts. By matching the retrieval method to the question, Adaptive-RAG makes sure answers are relevant. It also uses the newest available information. This adaptability greatly reduces the chance of getting old or generic answers. Adaptive-RAG sets a new standard for accurate automated question answering.
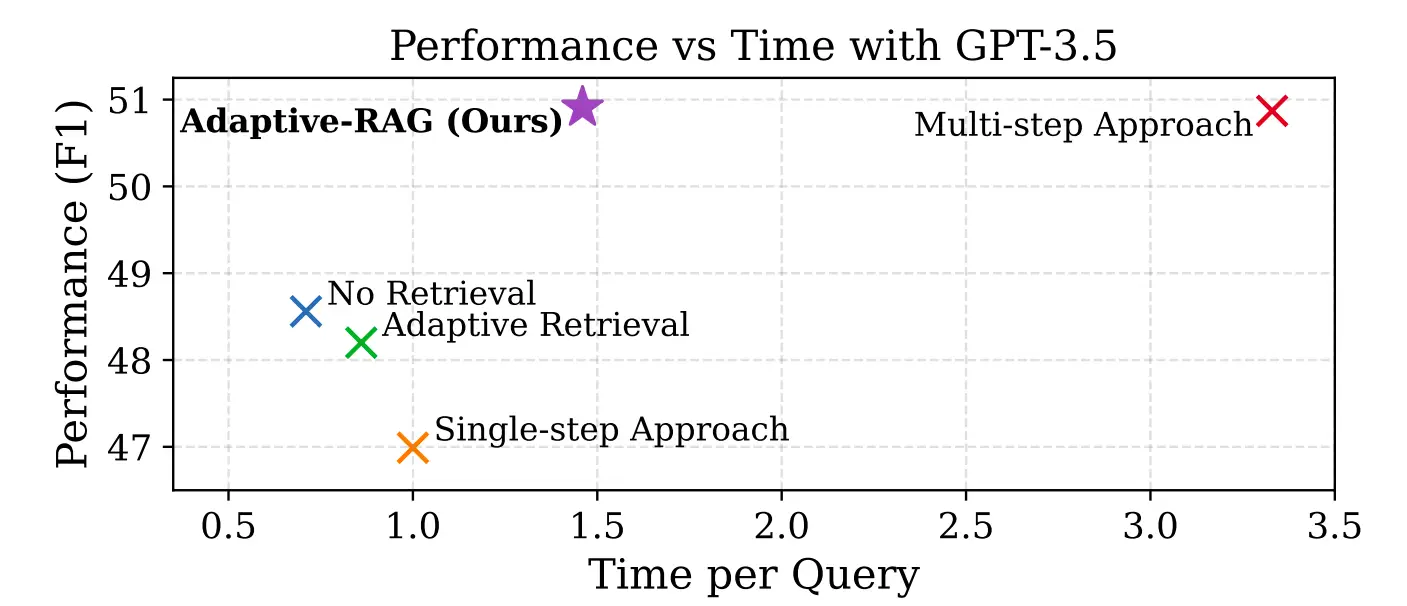
The image from the research paper compares different RAG approaches. Adaptive RAG excels in both speed and performance.
What is Adaptive RAG?
Adaptive Retrieval-Augmented Generation (Adaptive RAG) is a RAG architecture designed to improve how large language models (LLMs) handle queries. It adjusts the strategy for answering questions based on their complexity.
The Key Idea of Adaptive RAG
Adaptive RAG selects the best approach for answering a query, whether it’s simple or complex. A classifier evaluates the query and decides whether to use a straightforward method, a single-step retrieval, or a multi-step process.
Comparison with other approaches
As shown in the above image, here’s the comparison of adaptive RAG with a single-step, multi-step approach.
1. Single-Step Approach
This method retrieves information in one go and pass it to the LLm to generate an answer directly. Although it works well for simple questions like “What is Agentic RAG?”, it struggles with complex queries. For instance “What is the use of Agentic RAG in the healthcare sector?” due to lack of reasoning on the retrieved information.
2. Multi-Step Approach
This method processes all queries through multiple retrieval steps, refining answers iteratively. While effective for complex queries, it can waste resources on simple questions. For instance, repeatedly processing “What is Agentic RAG?” is inefficient.
3. Adaptive Approach
A classifier determines the complexity of the query and selects the appropriate strategy:
- Straightforward Query: Generates an answer without retrieval (e.g., “What is the capital of India?”).
- Simple Query: Uses a single-step retrieval.
- Complex Query: Employs multi-step retrieval for detailed reasoning.
- Advantages: This method reduces unnecessary processing for simple queries while ensuring accuracy for complex ones.
Adaptive RAG Framework
- Classifier Role: A smaller language model predicts the complexity of the query. It learns from past outcomes and patterns in the data.
- Dynamic Strategy Selection: The framework conserves resources for simple queries and ensures thorough reasoning for complex ones.
RAG System Architecture Flow from LangGraph
Here’s another example of an adaptive RAG System architecture flow from LangGraph:
Adaptive RAG System Architecture Flow:
1. Query Analysis
The process begins with analyzing the user query to determine the most appropriate pathway for retrieving and generating the answer.
- Route Determination
- The query is classified into categories based on its relevance to the existing index (database or vector store).
- Related to Index: If the query is aligned with the indexed content, it is routed to the RAG module for retrieval and generation.
- Unrelated to Index: If the query is outside the scope of the index, it is routed for a web search or another external knowledge source.
- Optional Routes: Additional pathways can be added for more specialized scenarios, such as domain-specific tools or external APIs.
2. RAG + Self-Reflection
If the query is routed through the RAG module, it undergoes an iterative, self-reflective process to ensure high-quality and accurate responses.
- Retrieve Node
- Retrieves documents from the indexed database based on the query.
- These documents are passed to the next stage for evaluation.
- Grade Node
- Assesses the relevance of the retrieved documents.
- Decision Point:
- If documents are relevant: Proceed to generate an answer.
- If documents are irrelevant: The query is rewritten for better retrieval and the process loops back to the retrieve node.
- Generate Node
- Generates a response based on the relevant documents.
- The generated response is evaluated further to ensure accuracy and relevance.
- Self-Reflection Steps
- Does it answer the question?
- If yes: The process ends, and the answer is returned to the user.
- If no: The query undergoes another iteration, potentially with additional refinements.
- Hallucinations Check
- If hallucinations are detected (inaccuracies or made-up facts): The query is rewritten, or additional retrieval is triggered for correction.
- Does it answer the question?
- Re-write Question Node
- Refines the query for better retrieval results and loops it back into the process.
- This ensures that the model adapts dynamically to handle edge cases or incomplete data.
3. Web Search for Unrelated Queries
If the query is deemed unrelated to the indexed knowledge base during the Query Analysis stage:
- Generate Node with Web Search: The system directly performs a web search and uses the retrieved data to generate a response.
- Answer with Web Search: The generated response is delivered directly to the user.
In summary, Adaptive RAG is a smart framework that enhances response quality and efficiency by adapting to the complexity of queries. Now let’s build a RAG application using the Adaptive-RAG strategy. Our application sends user questions to the best data source. Here’s the setup:
Implementation Steps
Here’s a breakdown of how we build the application using the LangGraph framework:
- Indexing Documents: We start by indexing documents with ChromaDB, a vector database in LangChain. This lets us quickly find relevant documents for a user’s question.
- Routing: The key part of our application is sending each question to the right place. This could be our web search or our internal vector database.
- Retrieval Grader: We use a retrieval grader to check if the retrieved documents are relevant. It gives a simple “yes” or “no” score.
- Generation: To create answers, we combine the prompt, the language model (LLM), and the data from the vector database or web search. This builds a clear and relevant response.
- Hallucination Grader: To make sure the information is correct, a hallucination grader checks if the answer is based on facts. It also gives a “yes” or “no” score.
- Answer Grader: An answer grader checks if the response fully answers the user’s question.
- Question Rewriter: This part improves the question. It rewrites the question to make it work better with the vector database.
- Web Search: The system finds relevant information online with the paraphrased question.
- Graph Representation using LangGraph: Finally, we use LangGraph to show how the application works. We define nodes and build a graph that shows the whole process.
Building an Adaptive RAG System with Self-Reflection
We will be implementing the Adaptive RAG System we have discussed so far using LangGraph. We will be loading some of our blog contents using PyPDFLoader into our vector database, the ChromaDB vector database. and also using the Tavily Search tool for web search. Connections to LLMs and prompting will be made with LangChain, and the agent will be built using LangGraph. For our LLM, we will be using ChatGPT GPT-4o, which is a powerful LLM that has native support for tool calling. Although, we can use any other LLM, it is advisable to use LLM finetuned for tool calling.
Workflow of Adaptive RAG
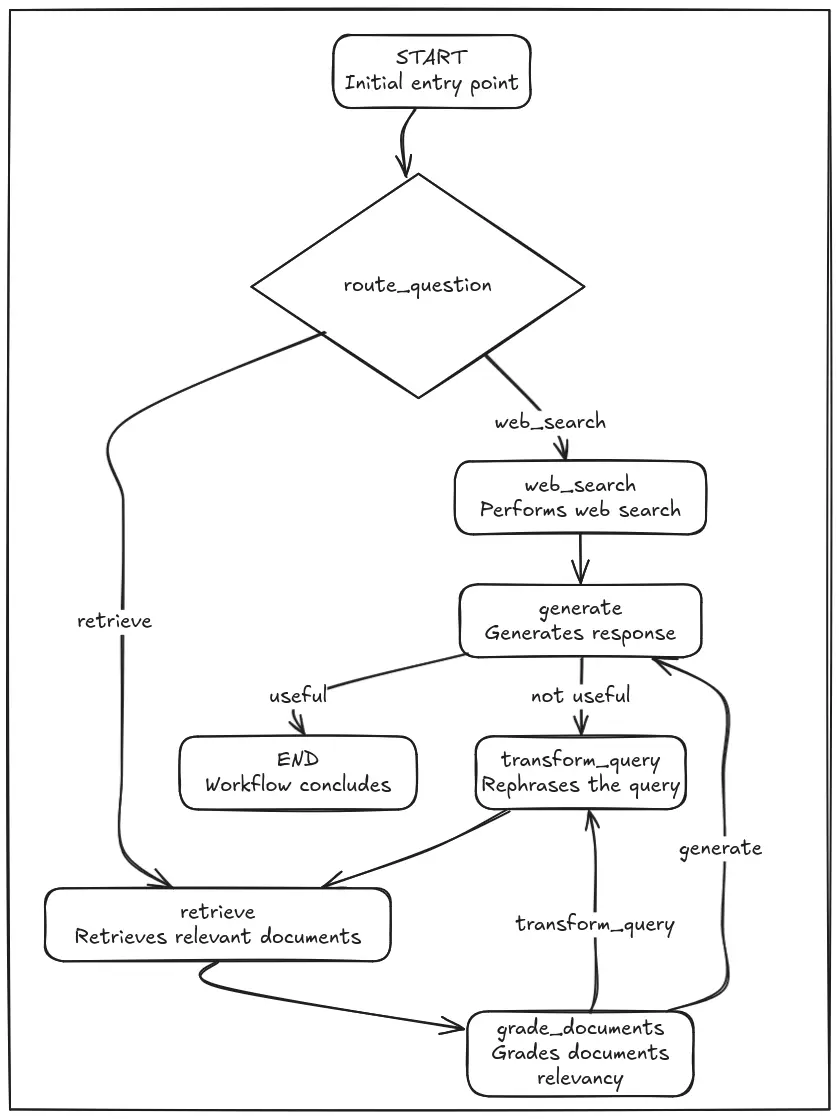
This image explains the workflow of the adaptive rag system.
Install OpenAI, ChromaDB, LangGraph and LangChain Dependencies
!pip install -U langchain_community tiktoken langchain-openai langchainhub langchain_chroma langchain langgraph tavily-python pypdfSet up OpenAI and Tavily API
from getpass import getpassOPENAI_KEY = getpass('Enter Open AI API Key: ')
TAVILY_API_KEY = getpass('Enter Tavily Search API Key: ')
Setting up environment variables
import os
os.environ['OPENAI_API_KEY'] = OPENAI_KEY
os.environ['TAVILY_API_KEY'] = TAVILY_API_KEYSet up OpenAI embeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
openai_embed_model = OpenAIEmbeddings(model="text-embedding-3-small")Load Knowledge Base
We have downloaded the blogs PDFs and made the pdfs documents available in a folder named “pdf” on Google Drive, you can download it from here.
Now upload the “pdf” folder in the colab.
After loading the pdfs, docs_list contains the documents loaded from the PDFs in the directory
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import PyPDFLoader
pdf_directory = "/content/pdf"
# Create a DirectoryLoader with PyPDFLoader as the loader
loader = DirectoryLoader(pdf_directory, glob="**/*.pdf", loader_cls=PyPDFLoader)
docs_list = loader.load()
# Now, docs_list contains the documents loaded from the PDFs in the directory
print(f"Loaded {len(docs_list)} documents.")
# Example: Print the first few pages of the first document (if it has pages)
if docs_list:
first_doc = docs_list[0]
if hasattr(first_doc, 'page_content'):
print(first_doc.page_content[:500]) # Print the first 500 characters of the first pageOutput
Loaded 60 documents. 5 Types of AI Agents that you Must Know About Introduction What if machines could make their own decisions, solve problems, and adapt to new situations just like wedo? This would potentially lead to a world where artificial intelligence becomes not just a tool but acollaborator. That’s exactly what AI agents aim to achieve! These smart systems are designed tounderstand their surroundings, process information, and act independently to accomplish specific tasks.
Let’s think about your daily life—w
Performing the Chunking using RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=300)
chunked_docs = splitter.split_documents(docs_list)
chunked_docs[67].page_contentOutput
# Instantiate tools docs_tool =
DirectoryReadTool(directory='/home/xy/VS_Code/Ques_Ans_Gen/blog-posts')\nfile_tool =
FileReadTool() search_tool = SerperDevTool() web_rag_tool =
WebsiteSearchTool()\nExplanations\ndocs_tool: Reads files from the specified
directory(/home/badrinarayan/VS_Code/Ques_Ans_Gen/blog-posts). This could be used
for reading past blogposts to help in writing new ones.\nfile_tool: Reads
individual files, which could come in handy for retrieving research materials or
drafts.\nsearch_tool: Performs web searches using the Serper API to gather data on
market trends in AI.\nweb_rag_tool: Searches for specific website content to assist
in research.\n# Create agents researcher = Agent( role="Market Research Analyst"
, goal="Provide 2024 market analysis of the\nAI industry", backstory='An expert
analyst with a keen eye for market trends.', tools=[search_tool,\nweb_rag_tool],
verbose=True )\nExplanations\nResearcher: This agent conducts market research. It
uses the search_too
Creating a Vector Store using Chroma
Storing vectors in Chroma DB using hnsw index for a better retrieval.
from langchain_chroma import Chroma
chroma_db = Chroma.from_documents(documents=chunked_docs,
collection_name="rag_db",
embedding=openai_embed_model,
# need to set the distance function to cosine else it uses Euclidean by default
# check https://docs.trychroma.com/guides#changing-the-distance-function
collection_metadata={"hnsw:space": "cosine"},
persist_directory="./rag_db")Here we set up a similarity_threshold_retriever that extracts the best chunks using a threshold value for similarity between user query and chunks.
similarity_threshold_retriever = chroma_db.as_retriever(search_type="similarity_score_threshold",
search_kwargs={"k": 3,
"score_threshold": 0.3})Lets Test our Retriever
query = "what is AI agents?"
top3_docs = similarity_threshold_retriever.invoke(query)
top3_docsOutput
[Document(id='f808a58f-69b9-4442-86b4-fdf3247bdffa', metadata={'creationdate':
'2025-03-06T11:05:04+00:00', 'creator': 'Chromium', 'moddate': '2025-03-
06T11:05:04+00:00', 'page': 0, 'page_label': '1', 'producer': 'Skia/PDF m83',
'source': '/content/pdf/Understanding LangChain Agent Framework.pdf',
'total_pages': 9}, page_content="AI Agent Terms\nHere’s the list of AI Agent
terms:\n1. AI Agent\nAn AI agent is a type of digital assistant or robot that
perceives its environment, processes it, and performsactions to accomplish
particular goals. An example is a self-driving vehicle that has cameras and
sensorsto drive on the road. It is an AI that is working to keep you safe in real
time.\n2. Autonomous Agent\nAn autonomous agent is an AI that operates on its own
and does not require human supervision. Anexample would be a package delivery drone
that decides on a specific route, avoids obstacles, and makesthe delivery without
any help.\nA I A G E N T S\nA R T I F I C I A L I N T E L L I G E N C E\nB E G I N
N E R"),
Document(id='eef333a4-e2b4-4876-924a-e02ab77052a9', metadata={'creationdate': '2025-
03-06T11:05:04+00:00', 'creator': 'Chromium', 'moddate': '2025-03-
06T11:05:04+00:00', 'page': 0, 'page_label': '1', 'producer': 'Skia/PDF m83',
'source': '/content/pdf/Understanding LangChain Agent Framework.pdf', 'total_pages':
9}, page_content="AI Agent Terms\nHere’s the list of AI Agent terms:\n1. AI
Agent\nAn AI agent is a type of digital assistant or robot that perceives its
environment, processes it, and performsactions to accomplish particular goals. An
example is a self-driving vehicle that has cameras and sensorsto drive on the road.
It is an AI that is working to keep you safe in real time.\n2. Autonomous Agent\nAn
autonomous agent is an AI that operates on its own and does not require human
supervision. Anexample would be a package delivery drone that decides on a specific
route, avoids obstacles, and makesthe delivery without any help.\nA I A G E N T
S\nA R T I F I C I A L I N T E L L I G E N C E\nB E G I N N E R"),
Document(id='2a9a3be4-2a61-4bed-8e46-804f34dc624c', metadata={'creationdate': '2024-
07-10T10:50:06+00:00', 'creator': 'Chromium', 'moddate': '2024-07-
10T10:50:06+00:00', 'page': 1, 'page_label': '2', 'producer': 'Skia/PDF m83',
'source': '/content/pdf/Build a Customized AI Agent Without Code Using
Relevance.ai.pdf', 'total_pages': 11}, page_content="Frequently Asked
Questions\nUnderstanding AI Agents\nAI agents are self-governing creatures that
employ sensors to keep an eye on their environment, processinformation, and
accomplish predefined goals. They can be anything from basic bots to
sophisticatedsystems that can adjust and learn over time. Typical instances include
recommendation engines likeNetflix and Amazon’s, chatbots like Siri and Alexa, and
self-driving cars from Tesla and Waymo.\nAlso essential in a number of sectors are these agents: UiPath and Blue Prism are examples of roboticprocess automation (RPA)
programs that automate repetitive processes. DeepMind and IBM Watson Healthare
examples of healthcare diagnostics systems that help diagnose diseases and recommend
treatments.In their domains, AI agents greatly improve productivity, precision, and
customisation.\nWhy AI Agents are Important?\nThese agents play a critical role in
improving our daily lives and accomplishing particular objectives.\nAI agents are
significant because they can:\nlowering the amount of human labor required to
complete routine operations, resulting in increasedproduction and
efficiency.\nanalyzing enormous volumes of data to offer conclusions and suggestions that support decision-making.\nutilizing chatbots and virtual assistants
to provide individualized interactions and assistance.\nenabling complex
applications in industries like as banking, transportation, and healthcare.\nIn
essence, AI agents are pivotal in driving the next wave of technological
advancements, making systemssmarter and more responsive to user
needs.\nApplications and Use Cases of AI Agents\nAI agents have a wide range of
applications across various industries. Here are some notable use cases:\nCustomer
Service: AI agents in the form of chatbots and virtual assistants handle customer
inquiries,resolve issues, and provide personalized support. They can operate 24/7,
offering consistent andefficient service.")]
query = "what is the capital of USA?"
top3_docs = similarity_threshold_retriever.invoke(query)
top3_docsLet’s now try a question that is out of context, such that no context documents related to the question are there in the vector database.
Output
[]
We can see that our RAG system is working well.
Creating Router
It will route the user query based on the nature of the query to Web Search or Vector Store
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Data model
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vectorstore", "web_search"] = Field(
description="Given a user question choose to route it to web search or a vectorstore.",
)
# LLM with function call
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)
# Prompt
system = """You are an expert at routing a user question to a vectorstore or web search.
The vectorstore contains documents related to AI agents, Agentic Patterns and Types of AI agents.
Use the vectorstore for questions on these topics. Otherwise, use web-search."""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
question_router = route_prompt | structured_llm_router
print(question_router.invoke({"question": "Who won the IPL 2024?"}))
print(question_router.invoke({"question": "What are the types of AI agents?"}))Output
datasource="web_search"datasource="vectorstore"
Retriever Grader
It indicates whether the query is relevant to retrieved documents or not by simple “yes” or “no” output.
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt
system = """You are a grader assessing the relevance of a retrieved document to a user question. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
question = "agentic patterns"
docs = similarity_threshold_retriever.invoke(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt})Output
binary_score="yes"
Generation Node
This piece of code is fetching rag prompt from Langchain hub and then generating answer using LLM
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)Output
Agentic patterns in AI design refer to strategies that enhance AI systems' autonomy
and effectiveness. The key agentic design patterns include the Reflection Pattern,
which focuses on self-evaluation and refinement of outputs, Tool Use, Planning, and
Multi-Agent Collaboration. These patterns enable AI models to perform complex tasks
by encouraging self-evaluation, tool integration, strategic thinking, and collaboration.
Hallucination Grader
Here we are checking if the generated answer contains hallucination or not which is a self reflection step:
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generated answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Prompt
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"documents": docs, "generation": generation})Output
GradeHallucinations(binary_score="yes")
Answer Grader
It denotes whether the provided answer is legit or not according to the question asked
# Data model
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer)
# Prompt
system = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"question": question, "generation": generation})Output
GradeAnswer(binary_score="no")
Question Re-Writer
It rewrites the question which contains more semantic information which is used if the answer grader tags the answer as not relevant.
# LLM
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Prompt
system = """You a question re-writer that converts an input question to a better version that is optimized \n
for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})Output
‘What are agentic patterns and how do they influence behavior or decision-making?’
Defining Search Tool
Here Tavily search tool is defined which will be used to search the web
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)Constructing the Graph using LangGraph
Capturing the flow in as a graph.
Defining the GraphState
- question: query of the user
- generation: LLM generated answer
- documents: list of retrieved documents
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]Creating functions for the graphs node.
- retrieve: Adds the retrieved documents to the graph state
- generate: Adds the generated answer to the graph state
- grade_documents: It updates the document key with only relevant documents
- transform_query: Rephrases the query which capture more semantic meaning
- web_search: It searches the web for the updated answer and updates the document key accordingly
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = similarity_threshold_retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
return {"documents": web_results, "question": question}Creating Edges Functions
- route_question: It directs the question to RAG or web search
- decide_to_generate: It denotes whether to generate the answer or rephrase it
- grade_generation_v_documents_and_question: It determines whether the generated answer is relevant to the question
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web_search"
elif source.datasource == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
Defining the Graph Architecture
We will look into the workflow Flow Description below:
Initial Routing:
- The workflow begins at the START node.
- The route_question function determines whether to proceed with a web_search or a retrieve operation based on the incoming question.
Data Acquisition and Processing:
- If web_search is chosen, the system performs a web search and then moves to the generate node.
- If retrieve is chosen, the system retrieves relevant documents from a vector store, which are then passed to the grade_documents node.
- The grade_documents node then determines if the flow should go to transform_query or to generate.
- If the flow goes to transform_query, then the query is transformed, and sent to the retrieve node.
Content Generation and Evaluation:
- The generate node creates a response based on the information gathered.
- The grade_generation_v_documents_and_question function assesses the generated content.
Decision and Termination:
- If the generated content is deemed useful, the workflow reaches the END node, concluding the process.
- If the generated content is deemed not useful, the workflow goes to transform_query node.
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
# "not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()Workflow Graph
Printing the workflow graph using draw_mermaid :
from IPython.display import Image, display, Markdown
display(Image(app.get_graph().draw_mermaid_png()))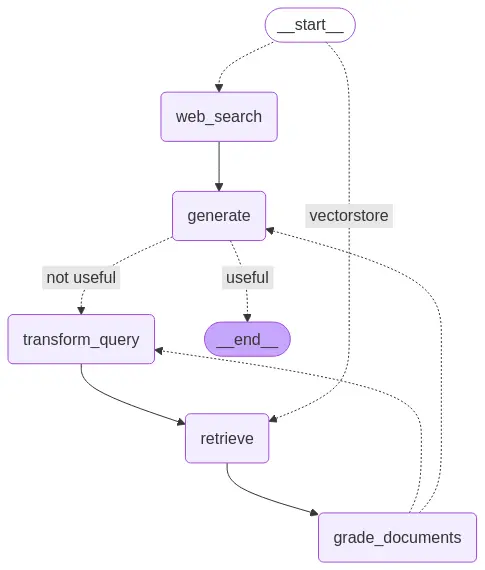
This image depicts the workflow of Adaptive RAG
Testing the Agent
from pprint import pprint
# Run
inputs = {
"question": "What are the types of Agentic Patterns?"
}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])Output
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('The types of Agentic Patterns are Reflection, Tool Use, Planning, and '
'Multi-Agent Collaboration.')from pprint import pprint
# Run
inputs = {
"question": "What player at the IPL 2024 hit maximum sixes?"
}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])Output:
---ROUTE QUESTION---
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
"Node 'web_search':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('Abhishek Sharma from Sunrisers Hyderabad hit the maximum sixes in IPL 2024, '
'with a total of 42 sixes.')Hence, we can see that our Adaptive RAG is working very well utilizing its self reflection capabilities to reason about the relevancy of output generated by LLM, Also utilizing the web search tool when retrieved documents are not that good.
Conclusion
Adaptive RAG Systems with LangGraph is an important advancement in creating intelligent question-answering systems. It selects the best retrieval method based on how complex a question is, which helps improve both speed and accuracy. This method overcomes the limitations found in traditional language models and basic retrieval-augmented generation systems. It provides users with relevant, current, and trustworthy information.
The examples and code resources available show how to implement Adaptive RAG Systems with LangGraph. This makes it easier to develop more effective and user-friendly AI applications. As AI technology progresses, methods like Adaptive RAG will be essential for building systems that can understand and respond to human questions more effectively.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕
Login to continue reading and enjoy expert-curated content.





